Czokowoko
Gruba ryba
Harry Potter z Krakowa lubi sobie odlecieć na #linkedin Jak tak czytam czasem w którą stronę zmierza to widzę że próbuje powoli miejsce po Filipiaku zająć xD
#programowanie

Harry Potter z Krakowa lubi sobie odlecieć na #linkedin Jak tak czytam czasem w którą stronę zmierza to widzę że próbuje powoli miejsce po Filipiaku zająć xD
#programowanie

Prawda jest taka:
Panstwa beda tworzyc wlasne EJAJE i to beda nowi nauczyciele.
Pan Jarosław dostosowuje sie do tej koncepcji, wiec staje się online kontent kreatorze, wy po prostu nie rozumiecie.
Zaloguj się aby komentować

No! Po zamianie Garmina Fenix 7X Solar na Apple Watch Ultra2 pojawił się problem dostępem do danych dla mojego bota(lokalnie postawiony OpenClaw)
Ogarniam sobie przez MCP dostęp do hevy gdzie trackuje siłownie, Myfitnesspal gdzie trackuje jedzenie oraz garmin gdzie sledze trening i aktywnośc.
Garmin fenix nie jest ukierunkowany na daily/wellbeing wiec go zmieniłem na Apple Watch ale dane z zegarka sa lokalnie storowane w iphone, nie wychodzą nigdzie. Przez to ze konto developera u apple to 99 usd rocznie, nie ma darmowych aplikacji które by wystawiały te dane w świat.
Do dzisiaj...znalazłem https://wellnessproject.ai
Szybie "rachu-ciachu" i mam mcp do swojego bota
Bawi się ktoś w takie cuda wianki tj analiza swoich poczyniań przez ejaje/boty?
#garmin #applewatch #silownia #trening #sztucznainteligencja #programowanie
K⁎⁎wa, my wszyscy robimy dokadnie to samo, a najwiecej na tym zarabia pieprzony Claude Code czy inny Codex.
Oczywiscie ze to robie. Mam tez standardowe "make me a billionaire AI trading bota". Jak narazie gowno.
Zaloguj się aby komentować
Zaloguj się aby komentować

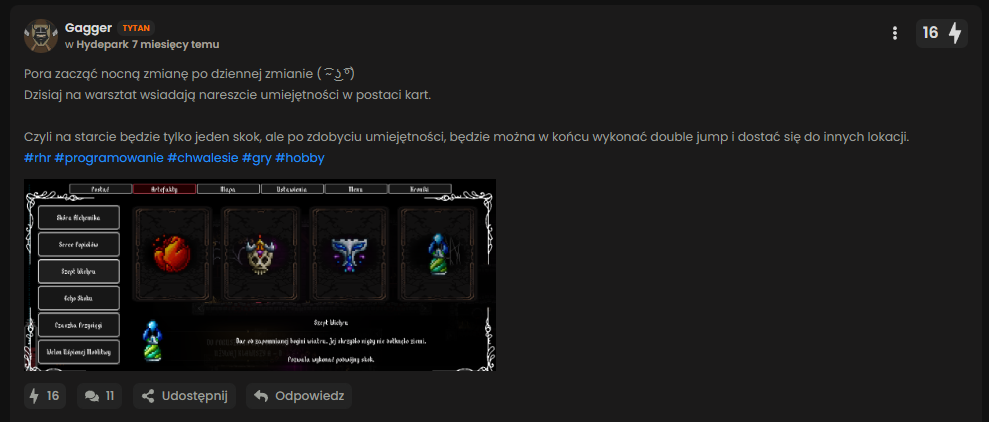
Dobra, zgredek może iść spać, dostał skarpetę!
W końcu uzupełniłem te nieszczęsne nazwy, opisy i działanie skilli.
Udało mi się też zaprojektować ekran z skillami, więc nie ma źle.
Jutro a znaczy się dziś, tylko pokolorować skille wedle typu, zaprogramować to tak, aby samo zaciągało nazwy.
Pokazywało umiejętność tak jak ma i gotowe.
Kolejny krok będzie skończony.
Trzeba iść spać, bo w tym tygodniu wyrobię prawie 60h ciągu w pracy.
#rhr #programowanie #pixelart #gry


@Gagger daj znać, jak na angielski będziesz chciał ogarnąć, mogę pomóc
Zaloguj się aby komentować
Tempo pracy nad grą nie zwalnia.
Ale są sprawy ważne i ważniejsze.
Ważne jest aby skończyć swoją grę i w końcu puścić DEMO
A najważniejsze jest oklepać Gomeza i jego przydupasów po raz drugi.
Teraz jako Mag Wody w stroju nekromanty ¯\_( ͡° ͜ʖ ͡°)_/¯
Poprogramuję jutro
#rhr #programowanie #gothic #gry

Dobrze by bylo jakbys sie wyrobil przed pazdziernikowym steam game festem, w sensie demo trailer i steampage gotowe maja byc
Zaloguj się aby komentować
Podoba mi się niepisana zasada w firmach IT, że jak PO mówi "masz tu libkę/SDK/moduł (czy cokolwiek ), powinno działać", to nigdy nie działa a potem zdziwienie że to tyle trwa XD
Dostałem kiedyś taska z integracją komponentu który miał trwać tydzień, a trwał pół roku mimo że mówiłem że bez sensu żebym naprawiał webowy komponent skoro ja jestem embeddedowcem a on i tak ma być generyczny xD
To jest chyba przekazywane na szkoleniach menadżerskich jak naszym rodzicom pakiety tekstów typu "Nudzi ci się? To się rozbierz i ubrania pilnuj".
#programowanie #korposwiat
@Czokowoko
Chyba ci sie can do attitude zgubiło gdzieś z rana.

@Czokowoko teraz jeszcze dodatkowo ai im podpowiada takie pomysły

@Czokowoko Embededowiec

Zaloguj się aby komentować

Kojarzycie cms do wszystkiego a zarazem do niczego #wordpress? Parę dni temu została opublikowana informacja o podatności sql injection w nim.
Tutaj trochę bardziej techniczny opis:
https://avlab.pl/dostep-do-bazy-i-systemu-po-kilku-zapytaniach-krytyczne-podatnosci-w-wordpress/
Jest dostępnych kilkanaście skryptów do hackowania, najpopularniejsze:
https://github.com/0xsha/wp2shell
https://github.com/Icex0/wp2shell-poc
Podatne są najnowsze gałęzie 6.8, 6.9, 7.0, czyli większość wordpressów na świecie jest bezpieczna, bo nikt ich nie aktualizuje.
#cyberbezpieczenstwo #programowanie #webdev

Miałem wymuszoną aktualizację do wersji 7.0.2 zanim sekurak to nagłośnił
Zaloguj się aby komentować
Kolejna nocka
I znowu 2:00, a dokładniej 2:20
A chłop znowu siedzi i kombinuje co by tu zrobić i jak to zrobić.
Tym razem wpada już końcówka projektowania GUI
Umiejętności gracza, ikony już mam gotowe, teraz przyszła pora na układ tego menu.
Pewnie znów do samego rana będę kombinował co i jak ogarnąć, poprzesuwam sporo elementów
A inne zastąpię czymś innym
#rhr #programowanie #pixelart #gry #chwalesie
Zaloguj się aby komentować
Może bym se w końcu w coś zagrał? ( ͠° ͟ʖ ͡°)
W końcu nie grałem na kompie od kilku miesięcy a zapłaciłem za niego jak za zboże.
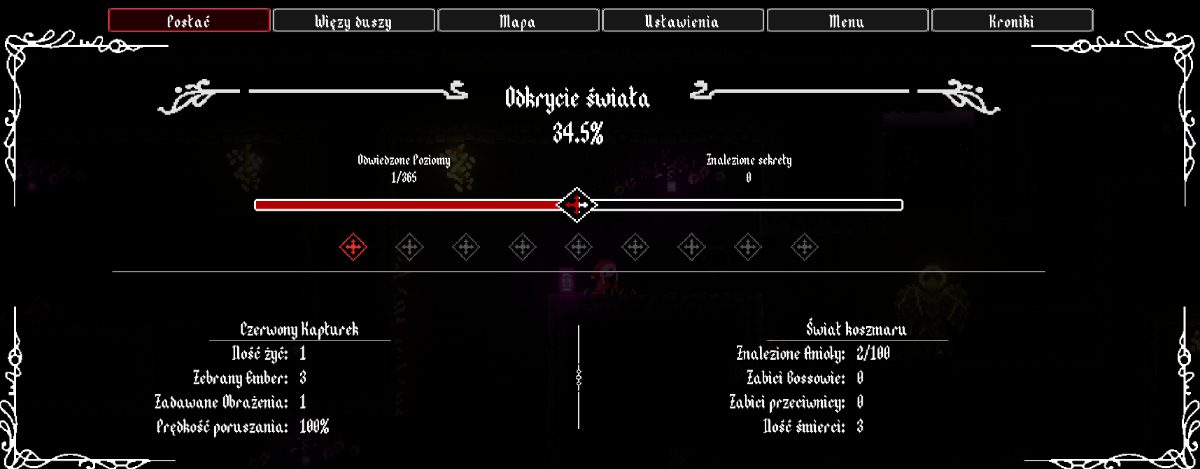
Dzisiaj skończyłem przebudowę pierwszej zakładki w menu gracza.
Wygląda o wiele lepiej niż ten haotyczny i brzydki wygląd.
Pasek postępu oczywiście na ten moment jako ozdoba, muszę przemyśleć ile elementów będzie składało się na postęp w grze.
A potem określić ich ilość, bo będą to na 100% znalezione anioły i sekrety, ale ich będzie to druga sprawa.
A potem trzeba to matematycznie ogarnąć (づ•﹏•)づ
No ale na ten moment, bo pewnie nie na dziś.
Ogarnąłem kolejną część w grze.
Pewnie wieczorem znów usiądę i będę siedział do 5 rano
#rhr #programowanie #pixelart #chwalesie
@Gagger w Rain World
Zaloguj się aby komentować

Cześć! Czy wiedzieliście, że dyletant oznacza osobę o płytkiej i powierzchownej wiedzy? A że to powtórzenie "płytkiej" i "powierzchownej", czyli masło maślane, ma swoją nazwę - pleonazm?
Kilka miesięcy temu zafascynowało mnie to, ile ciekawych polskich słów pozostaje dla mnie tajemnicą. Chciałem je poznać, żeby wzbogacić mój dość biedny zasób słownictwa i mówić ciekawiej. Szukałem wtedy też pomysłu na aplikację i tak oto doznałem epifanii. Tak powstało Słówko. - elegancki i przyjemny sposób na głębsze poznawanie języka.
- Codziennie rano otrzymujesz jedno nowe, stosunkowo mało znane i ciekawe słowo (np. wspomniany dyletant czy epifania).
- Do każdego słowa dołączona jest definicja, przykład użycia z życia wzięty oraz synonimy.
- Słowa możesz kolekcjonować, a następnie utrwalać za pomocą quizów i fiszek.
- Na podstawie Twoich wyników aplikacja generuje krzyżówki o różnym poziomie trudności, opierając się na słowach, które znasz słabiej lub lepiej.
- Całość można spersonalizować - przygotowałem ponad 9 motywów kolorystycznych, żeby nie wiało nudą.
Android (otwarta beta)
Wersja na telefony z Androidem jest aktualnie w otwartej fazie testowej. Będę ogromnie wdzięczny za Waszą szczerą opinię! Aby dołączyć, wystarczy dołączyć do naszej Grupy Google (https://groups.google.com/g/swko-na-android/about ) i kliknąć odpowiedni link pobierania w wiadomości powitalnej.
iOS (Prezent dla was)
Aplikacja w App Store jest płatna, ale dla pierwszych z Was przygotowałem 10 kodów promocyjnych na darmowy dostęp. To świetny moment, żeby zadbać o swoje słownictwo.
Poprosiłbym, żeby każdy kto wykorzysta któryś z kodów napisał go w komentarzu, by inni wiedzieli, że został on wykorzystany.
Słówko. można pobrać w Apple App Store pod tym linkiem (https://apps.apple.com/pl/app/s%C5%82%C3%B3wko-word-of-the-day/id6754086353 ). Więcej o aplikacji na extiri.com/slowko. Chętnie usłyszę, co o niej myślicie.
#tworczoscwlasna #programowanie #jezykpolski #android #ios #ciekawostki #rozdajo

@wiktor-wojcik dzięki za odpowiedź.
Nie wiem jak skorzystać z kodów.
PS jak kalikam w odzyskaj zakup to nic się nie dzieje oprócz animacji na zielono tego tekstu.
Ps po cholerę tak głośna muzyka na początek? Imho to niepotrzebne.
@wiktor-wojcik brzmi ciekawie, przedostatni kod na iOS wykorzystany
Co chlop zrobil. Nie wiadomo.
Zaloguj się aby komentować
W końcu!
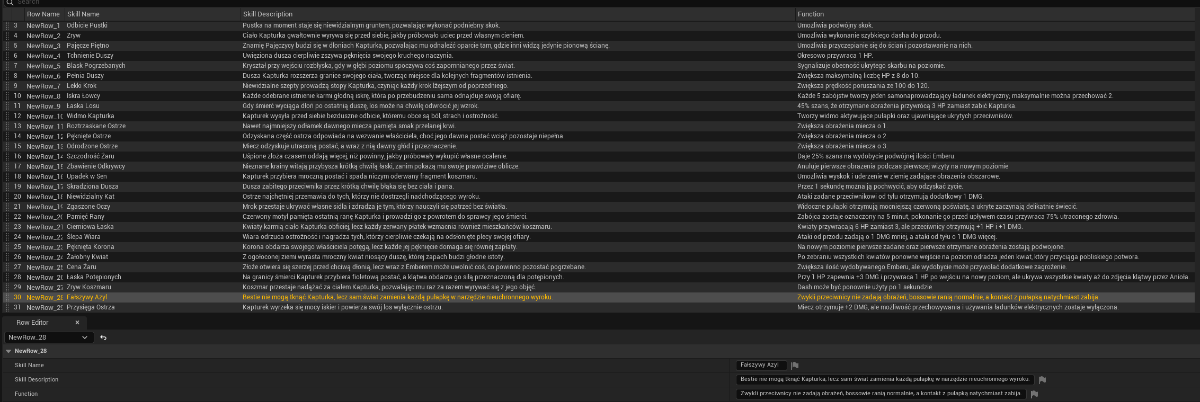
Skończyłem tworzyć ikony dla umiejętności bohaterki. ( ͡ಥ ͜ʖ ͡ಥ)
Zestaw 31 ikon.
Oraz zaprojektowałem w pełni system umiejętności tak, aby spełaniał większość wymogów.
Takich jak prosta głupota gracza, który mógłby się zablokować poprzez wybór umiejętności, czy brak odpowiedniej umiejętności do pokonania poziomu.
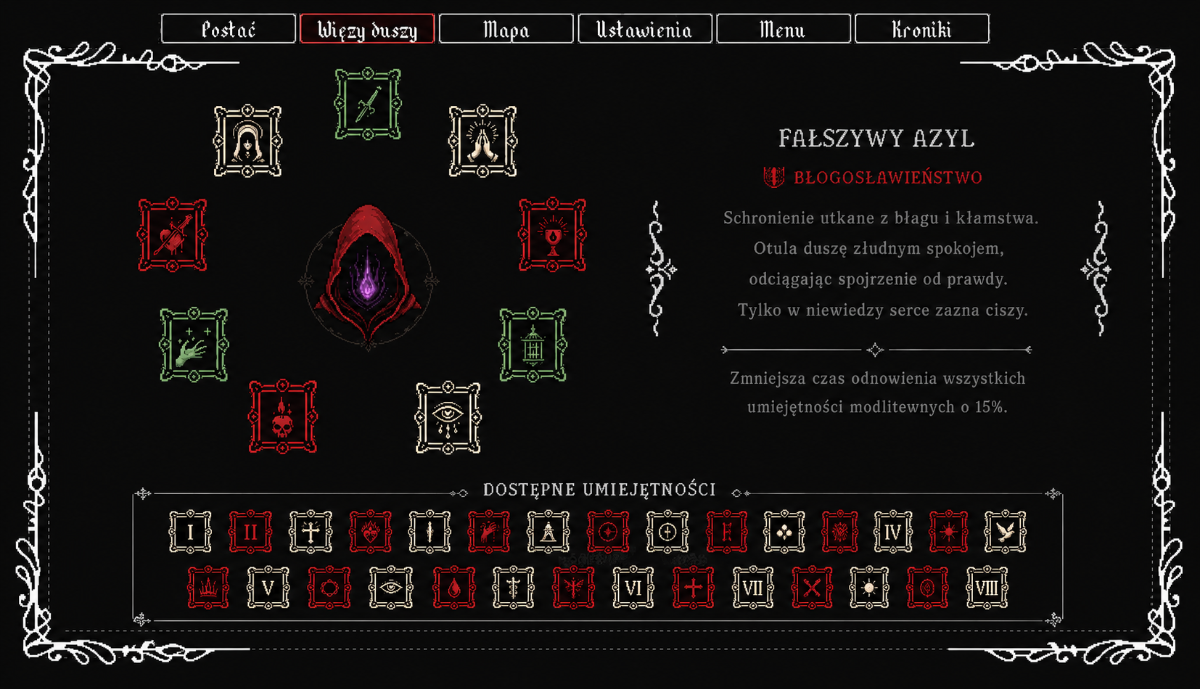
W grze znajdziemy 3 typy umiejętności.
Przebudzenia, Modlitwa oraz Błogosławieństwa.
Czym się będą różniły?
Przebudzenie, jest umiejętnością stałą, czyli tym zabezpieczeniem przed głupotą gracza.
Będą tu 3 umiejętności, umieszczone na stałe, ale dostępne dopiero po odblokowaniu
Podwójny skok, Dash oraz trzymanie się ścian.
Brak możliwości edycji czy wyłączenia.
Ma to na celu ograniczyć problem z graczem, który nie wybrał podwójnego skoku i wszedł w miejsce, gdzie nie może opuścić poziomu właśnie z powodu braku tej umiejętności.
Modlitwa, tutaj jest największe pole popisu
20 różnych modlitw, które ułatwiają grę, wybrać można tylko 2 z nich jednocześnie.
Będą tutaj umiejętności takie jak ochrona przed kwasem, ten domyślnie zabija gracza natychmiastowo, niezależnie od ilości HP, po aktywacji, kwas zabiera tylko 1HP, bądź umiejętność pozwalająca aktywować pułapki wysyłając sobowtóra gracza.
Błogosławieństwa
Najpotężniejsze i najgroźniejsze z nich, jest ich 8 i wybrać możemy 3 z nich jednocześnie.
W przeciwieństwa do modlitw, te mają także negatywne skutki.
Wybierając umiejętność, wybieramy także jej negatywną stronę.
Czyli potwory mogą zadawać 0DMG (poza bossami oczywiście) nie będą w stanie nas skrzywdzić.
Ale każda pułapka w grze jest śmiertelna, więc zabija gracza natychmiast.
Możemy aktywować także umiejętność, która pozwoli nam zebrać 6 kwiatów życia zamiast tylko 3
Ale przy każdym kwiatku czekać będzie przeciwnik, dość trudny do pokonania.
Albo podnosiły swoje obrażenia o +3 DMG
Ale każdy przeciwnik zyskuje +1HP oraz +1DMG
Dlaczego są 3 kategorie?
Ponieważ pierwsza blokuje głupotę gracza
Druga pozwala dodać coś do swojej postaci, bez kary.
A trzecia zmienia zasady gry, pozwala zyskać przewagę ale także zwiększyć poziom trudności.
A jak przypominam w grze będzie jeden, nie będzie zmiany poziomu trudności.
Dodatkowo jest to lepszy system niż poprzedni, gdzie wybieraliśmy po prostu 4 umiejętności z 9 dostępnych.
Odblokowanie umiejętności stałych, będzie następowało po pokonaniu przeciwników, wraz z fabułągry.
Jest to niezmienny element.
Natomiast zdobywanie pozostałych, będzie odkrywaniem świata gry.
Jedne będą ukryte w sekretnych pokojach, inne w zakamarkach poziomów.
Ich zdobycie nie jest wymagane do ukończenia gry.
#rhr #programowanie #pixelart #nocnazmiana

@Gagger bardzo ładne cieniowanie kapturka i pola siłowego i wgl.
Robisz to w normalnej rozdzielczości i potem zmniejszasz\pixelizujesz? W sumie nigdy się w pixelozę nie bawiłem.
Zaloguj się aby komentować

@vrkr gdzie takie cuda? XD
Zaloguj się aby komentować
Dokładnie 7 miesięcy temu zacząłem pracę nad umiejętności.
Siedziałem po nocach myślałem jak to ma wyglądać.
Pamiętam problemy, które tam były.
Brak pomysłu jak to zrobić, jak to ma wyglądać.
Prostackie karty, źle dopasowane, rozciągnięte.
Dzisiaj przyszedł ten dzień, w którym wiem ja kto ma wyglądać.
Dopasowałem do siebie ikony umiejętności oraz pojemniki, które mają je trzymać.
To jes pierwszy raz od 9 miesięcy robienia tej gry, kiedy był efekt zaskoczenia, jak dobrze to wygląda.
Ikony pasujące do lore gry, do głównej bohaterki.
Pokazują nie tylko, że czerwony kapturek jest główną postacią, ale prosto sygnalizują co dają.
Ikona z kwasem, sygnalizować będzie brak natymiastowej śmierci od dotknięcia kwasu, zamiast tego zabierać będzie 1HP, druga działa tak samo, ale z lawą.
Kolejne to podwójny skok, dash, możliwość trzymania się ścian.
Dzisiaj podrzucę wam tylko screena z pierwszego posta, sprzed 7 miesięcy, kiedy pierwszy raz próbowałem to ogarnąć.
Oraz zestaw ikonek.
Jutro też muszę coś napisać, a nie będę miał co, więc wrzucę wam jak wygląda menu z wyborem umiejętności ( ͡~ ͜ʖ ͡°)
#rhr #programowanie #pixelart #gry #chwalesie


Ikony sztos, wyglądają zajebiecie
@Fen Za jutro dodam jak to wygląda w grze.
Bo męczyłem się jeszcze dziś z całym UI i nazwami umiejętności.
A jest ich 31 łącznie.
I żebyś siedział zniecierpliwiony i zaciekawiony.
Wyglądają epicko.
Ikony są dograne perefekcyjnie
Nazwy są tematyczne i klimatyczne.
Najważniejsze są kategorie umiejętności, są 3.
Każda działa inaczej, ma co innego.
Muszę to tylko dodać do gry i stworzyć wpis.
Siedziałem nad tym do 3 w nocy
Zaloguj się aby komentować


EventCatalog to narzędzie do dokumentowania architektury systemów w podejściu Documentation as Code. Pozwala opisywać zdarzenia, komendy, usługi, domeny i przepływy między nimi. Dzięki temu wiedza o architekturze trzymana jest blisko kodu i jest łatwiejsza w utrzymaniu.
W najnowszym artykule...
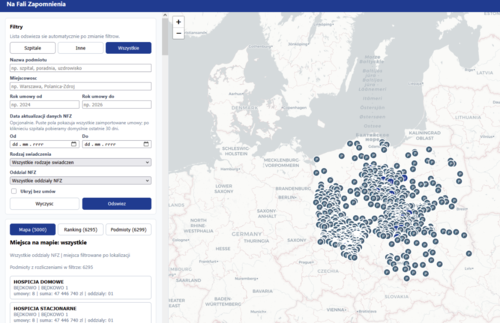
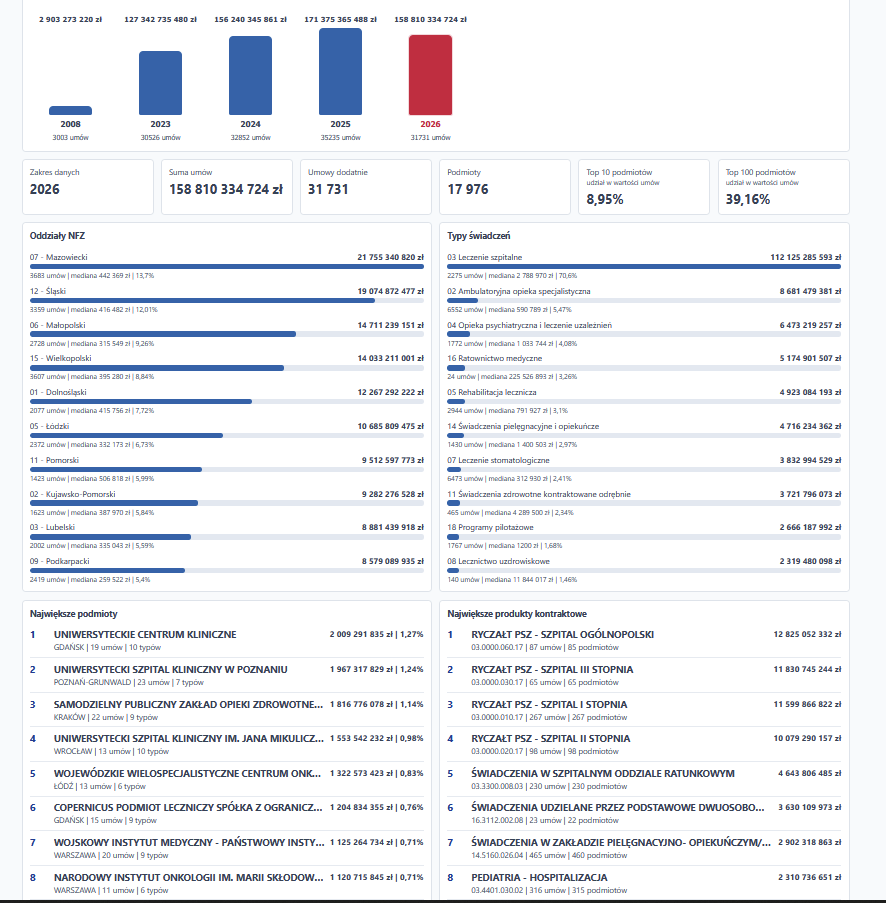
Jakiś czas temu pisałem, że tworzę aplikację do agregowania danych w jednym miejscu z wszystkich kontraktów NFZ.
https://www.hejto.pl/wpis/robie-sobie-w-wolnej-chwili-aplikacje-do-pobierania-danych-z-kontraktow-zawartyc
Obecnie jestem na etapie dodawania jak największej ilości danych przydatnych do analityki ale że samych danych nie ma jakoś super dużo, zacząłem podróż po stronach rządowych, z dostępem do API albo wystawioną bazą danych do pobrania.
Powiem wam, że do poziomu NFZ jest całkiem ok ale potem zaczynają się schody xd oto kilka punktów.
1. Głównym problemem jest brak centralnej agregacji danych, każdy podmiot publiczny ma swoją własną stronę BIP, co znacząco utrudnia przeszukiwanie danych. Ale brak API to jedno ..
2. Okazuje się że nawet jak stwierdzę "dobra olać to, spróbuję nawet znaleźć po prostu jakiekolwiek dane na ich stronach", to okazuje się że jeśli podmiot zatrudnia lekarzy JDG albo spółki to takie umowy są wyłączone z ustawy o zamówieniach publicznych xd
3. Finalnie jeśli chcesz się dowiedzieć czegoś więcej, musisz wysłać do nich zapytanie o dostęp do informacji publicznej, bo na to muszą ci odpowiedzieć.
Mam jeszcze kilka innych przemyśleń jak działa u nas dostęp do publicznie dostępnych danych ale to w innym poście za jakiś czas XD Ogólnie dużo różnych danych jest dostępnych ale to jednak trochę złudne wrażenie (ja mam), bo najsensowniejsze są gatekeepowane dalej.
Może w przyszłym tygodniu uda mi się ją udostępnić, jak przejdzie testy jakości u mojej przyszłej żony XD
PS. Szukam sensownego VPSa do postawienia dockera.
#lekarze #programowanie

@Czokowoko no ja bym się chyba po tym poddał;
okazuje się że jeśli podmiot zatrudnia lekarzy JDG albo spółki to takie umowy są wyłączone z ustawy o zamówieniach publicznych
Wydaje mi się że wszystkie wysokie kontrakty będą z działalnościami - 14% ryczałtu jest wręcz stworzone pod prace konsultowania pacjentów.
Zaloguj się aby komentować

W obecnej #pracbaza nie mieli dla mnie zleceń i się pożegnaliśmy. Szuka ktoś może ML engineera / Data scientista? Mam 3 lata doświadczenia w Pythonie, i pracowałem na każdym etapie projektowania, trenowania, poprawiania i utrzymywania modeli ML. Robiłem analizy danych i wizualizacje w R. Robie magistra z matematyki ze specjalizacją w analizie danych (za rok mam sie bronić) oraz jestem w miarę ogarniętym programistą.
Tworzyłem toole dla agentów, implementowałem LLM-y (w sensie, dodawałem funkcjonalność np. chatbota używając cudzego LLM-a), rozwiązywałem problemy regresji czy klasyfikacji, a także badałem opcje robienia Table Structure Recognition dla skomplikowanych tabeli
#programowanie #ai #sztucznainteligencja

Szukajcie a znajdziecie, tylko się nie poddawaj. Walcz o swoje i pamiętaj że górne widełki w ogłoszeniu to twoje oczekiwania finansowe. Ustaw alerty, rób cvke pod ogłoszenie i jak baba z HR pyta czy czegoś używałeś to mówisz że tak, chociażbyś nie wiedział co to - ona też nie wie a ty możesz to ogarnąć przed rozmową techniczną.
Zaloguj się aby komentować

@Ragnarokk I'm tired bro..
przecież się z tego już rok temu wszyscy nabijali, teraz dopieor na hejto dosżło xD

@Eruanno No to najwyraźniej nie wszyscy

Ej bo ja tu widzę duży hejt w komentarzach ale większość osób chyba nie rozumie po co powstał ten format. To nie ma być następca JSONa, YAMLa i innych. To jest specjalny format do oszczędzania tokenów gdy promptujesz dużo danych do modelu. Domyślnie używa się jsona i przed promptem robisz konwersje i to potrafi często oszczędzić nawet do 60% tokenów.
https://github.com/toon-format/toon

@Catharsis Fajnie, wciąż to CSV with extra step
To nie hejt, hejt jest zarezerwowany na XMLa
@Ragnarokk
wciąż to CSV with extra step
No ale dokładnie to napisali twórcy w podlinkowanym readme. Ten format jest lekko większy niż CSV ale pozwala na lepsze i dokładniejsze przekazanie informacji do modelu. Tam jest podane parę testów i benchmarków i w większości modele lepiej sobie radzą z odczytem danych w TOON niż CSV. Minimalnie ale jednak lepiej więc nie jest to bezsensowne.
A XML to wiadomo xD
Zaloguj się aby komentować

Hejka, Chrome po mały u poprawkach zaakceptował mój dodatek do chroma, także jak kupujecie na allegro dużo pierdół to zapraszam to korzystania.
Link : https://chromewebstore.google.com/detail/aco-cart-optimizer/gapkgkgimcaneodifejeanibcpeocngi
Wersje na Firefox i edge ciągle czekają na weryfikację, a port na androida już jest w trakcie co przedstawia screenshot :)
W razie jakichkolwiek pytań chętnie odpowiem.
Wołam @lipa13 @pigoku
#diy #allegro #programowanie #chwalesie

@green-greq poproszę o dodanie tagów
@green-greq Dzięki za zawołanie. Na pewno przetestuję w wolnej chwili

@green-greq wołaj jak będzie na lepszejszych przeglądarkach dostępne

@HmmJakiWybracNick Firefox się opierdala ze sprawdzeniem i podobno z 2 miesiące można czekać. Jak chcesz mogę podesłać Ci link do zipka i wygrasz sobie jako tymczasowe
@green-greq Meh, poczekam. I tak zamawiam za dużo pierdół z allegro/amazona, że próbuję zrobić aktualnie dekoks zakupowy i wyprzedaję rzeczy na olx i wydaję tylko tak zarobione pieniądze na nowe zakupy XD
Zaloguj się aby komentować
Dlaczego współczesne usługi oparte o hindi operator i AI są takie gówniane?
Bo hindi prompt manager nie wie co klepie.
Jest sobie usługa serwerów vps zza wielkiej wody. Dostaje w poniedziałek email, że dzisiejszej nocy będzie przerwa techniczna bo robią upgrade systemów. Serwer w lokalizacji europejskiej. Nie pierwszy i nie ostatni raz.
Jakie było moje zdziwienie jak rano zobaczyłem, że serwer leży. Otwieram konsole, a tam wisi na konfiguracji uefi. Super.
Reset, znowu wróciło. Pewnie boot menu się wysypało. Sprawdzam konfigurację, a tam brak mojego systemu. To menu dysków, nie widzi dysku.
Grubo.
To czas na jakieś rescue. Biorę jakieś iso od nich. Dysk widzi, to chociaż tyle. No to reinstall gruba. Linuksowe środowisko chroot nie chce się podnieść dla uefi, bo iso jest za stare xD. Stabilne usługi.
Próbuje wrzucić swoje iso z urla. Download failed.
Za⁎⁎⁎⁎ście.
Biorę jakieś inne ich iso. Podniosło się. ping 8.8.8.8 jest. To próbuje pobrać gotowy skrypt do naprawy i nie rozwiązuje się nazwa dns. Jak zwykle to wina dns. Zmiana serwera na 8.8.8.8 poszło. Przeinstalowałem reboot i zastałem pusty grub. Zrobiło się jakby świątecznie.
To szukamy dysku
ls
ls (hd0,gpt1)/
ls (hd0,gpt2)/
ls (hd0,gpt3)/
jest i on, to
configfile (hd0,gpt2)/boot/grub/grub.cfg
wstało menu, system się odpaliłem.
reinstalacja grub
grub-install --target=x86_64-efi --efi-directory=/boot/efi --bootloader-id=debian
update-grub
Przy okazji sprawdzenie czy wszystko wstało i update systemu. Okazuje się, że pociągnęło z dhcp adresy dns, które nie działają.
Wychodzi na to, że tak zaktualizowali systemy matki pod wirtualizacje, że uwalili konfiguracje uefi dla maszyn wirtualnych. Dla swoich też xD
#programowanie #linux #hosting

niepoważni xD

@30ohm - dalej używasz znienawidzonego Debiana?
@koszotorobur to jeden z dwóch hostów który nie przeinstalowałem jeszcze. Problemem jest że to środowisko do monitoringu i trzeba przenieść dane a ja nie mam czasu na to. Poza proxmox przeniosłem wszystko co chodziło na debianie i Ubuntu w rok czasu na Alma linux
@30ohm - a to że Alma budowana jest ze źródeł RHELa i jak RHEL jest mocno zintegrowana z systemd Ci nie przeszkadza?

@30ohm jak kiedyś byłem w zespole gdzie był senior Java software developer - wiadomo dobrze opalony. Pierwszy problem - jak obsługiwać intelij
Zaloguj się aby komentować
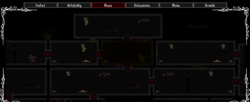
W końcu! (╯°□°)╯︵ ┻━┻
Znowu się zasiedziałem i nie wyśpię się kolejny raz, ale warto było.
Coś co nie dawało mi spokoju od ponad 6 miesięcy.
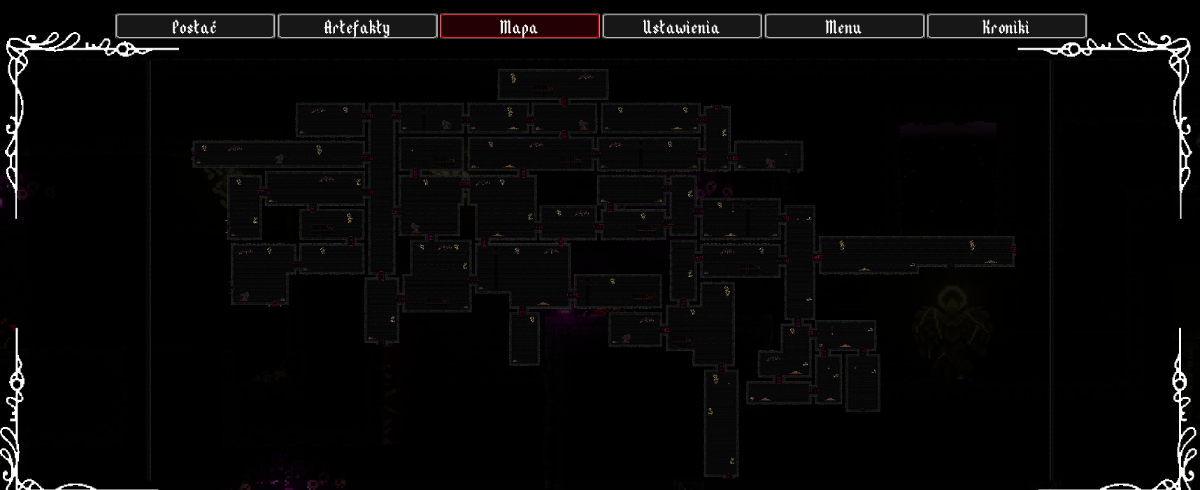
Gotowa mapa, jej pomysł, wykonanie, działanie.
Wcześniej mapa była mało czytelna, znajdowało się na niej 365 obonych poziomów.
Dostrzec gdzie jesteśmy było okropnie ciężko.
Jak to rozwiązałem?
Podzieliłem całą mapę na sektory biomów.
Teraz siedząc w biomie zamkowym, widzimy poziomy tylko tego biomu
Przechodząc na zielone polany, widzimy mapy zielonych polan.
Dodatkowo poprawiłem przesuwanie mapy, teraz działa płynnie, nic nie zacina.
Można mapę powiększać.
Ale co najważniejsze, poziom z graczem w końcu jest podświetlony.
Widać gracza na danej mapie.
Na ten moment zmieniony kolor na złoty jedynie.
W przyszłości ma być to inny znacznik, inny kolor albo samo obramowanie nawet.
Samo oznaczanie poziomu daje kolejny ciekawy punkt.
Anioły, które służą do odradzania się postaci oraz teleportacji mogą być porządnie oznaczone na mapie.
Jasno-złotym kolorem, czy migającym światłem.
To co widać, oczywiście nie będzie widoczne w grze.
Poziomy zostaną ukryte i pokazane będą w momencie gdy gracz je odwiedzi.
#rhr #programowanie #komputery #pixelart
Wygląda to bardzo, bardzo dobrze!!! Zaostrzasz apetyt z każdym wpisem!
@Fen Już coraz bliżej DEMO niż dalej.
Mapa - gotowa
Przeciwnicy - w 90% gotowi
Systemy przejścia między poziomami, zbieranie życia i emberu, jakieś platformy ruchome, pułapki i ukryte miejsca na poziomach - gotowe
Dzisiaj biorę się za UI umiejętności.
Muszę zmienić wygląd i zaprojektować ikony.
Zaloguj się aby komentować