
@vrkr jprdl, niektórzy to głowę mają nie wiadomo po co bo mózgu tam 404 not found
@vrkr zawsze mnie to zastanawiało. Wystarczająco wiedzy, by znaleźć i dodać issue, a za mało, żeby znaleźć sekcję releases.
Jakby trafili do roku 2000 z 10 guziczkami download, z których jeden jest prawdziwy, to by zginęli.
Zaloguj się aby komentować
za⁎⁎⁎⁎sta platforma #github nie może stworzyć pull requesta xD
co polecacie? selfhosted odpada. GitLab znam, więc to będzie mój domyślny wybór, bo tak się żyć nie da.
zapraszam na imprezę https://ghstatus.party/
#programowanie #gownowpis

@wombatDaiquiri Ja mam setup Forgejo(Gitea) self-hosted z push-mirror na GH i GL. Co jest nie tak z GL, btw?

@wombatDaiquiri mam zamiar postawić bloga na jekyllu, początkowo miał być hostowany na githubie, ale w sumie to się zastanawiam, czy to jednak tego nie zrobić na gitlabie

codeberg.org?
Zaloguj się aby komentować

wrap lines
Zaloguj się aby komentować
Elo #programowanie
#github chce trenować AI na Twoim kodzie. Można się wypisać
On April 24 we'll start using GitHub Copilot interaction data for AI model training unless you opt out. Review this update and manage your preferences in your GitHub account settings .
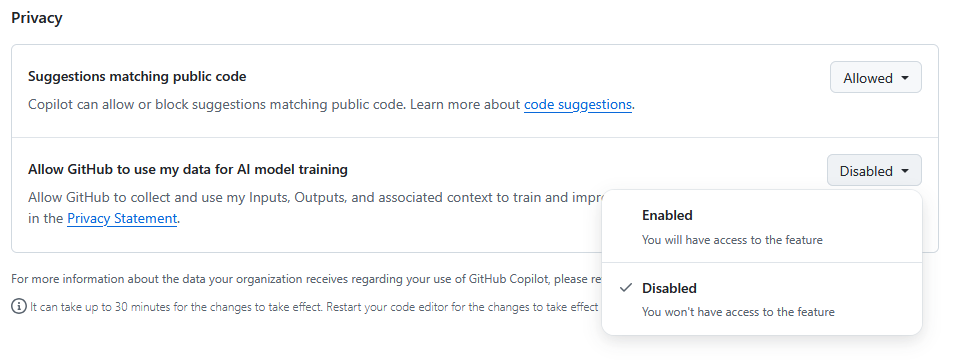

Niech się uczy na moim gówno legacy kodzie.

Odkąd githuba przejął Microsoft to generalnie używam alternatyw.
Po za tym nie wierzę w ogóle w to, że ta flaga jest jakkolwiek respektowana xD

Hmm mam wrażenie, że robicie wszyscy z igły widły. Tam jest napisane, że będzie tylko używać danych z waszych interakcji z Copilotem a nie całego waszego kodu. Czyli wasze prompty plus odpowiedzi AI. I jest to opcjonalne, uczciwie uprzedzili że będą tak robić i dali możliwość wyłączenia tego. Przecież większość AI w jakiś sposób używa podobnych danych a zwłaszcza w darmowych wersjach. Zobaczcie sobie regulaminy wszystkich tych usług.
Zaloguj się aby komentować

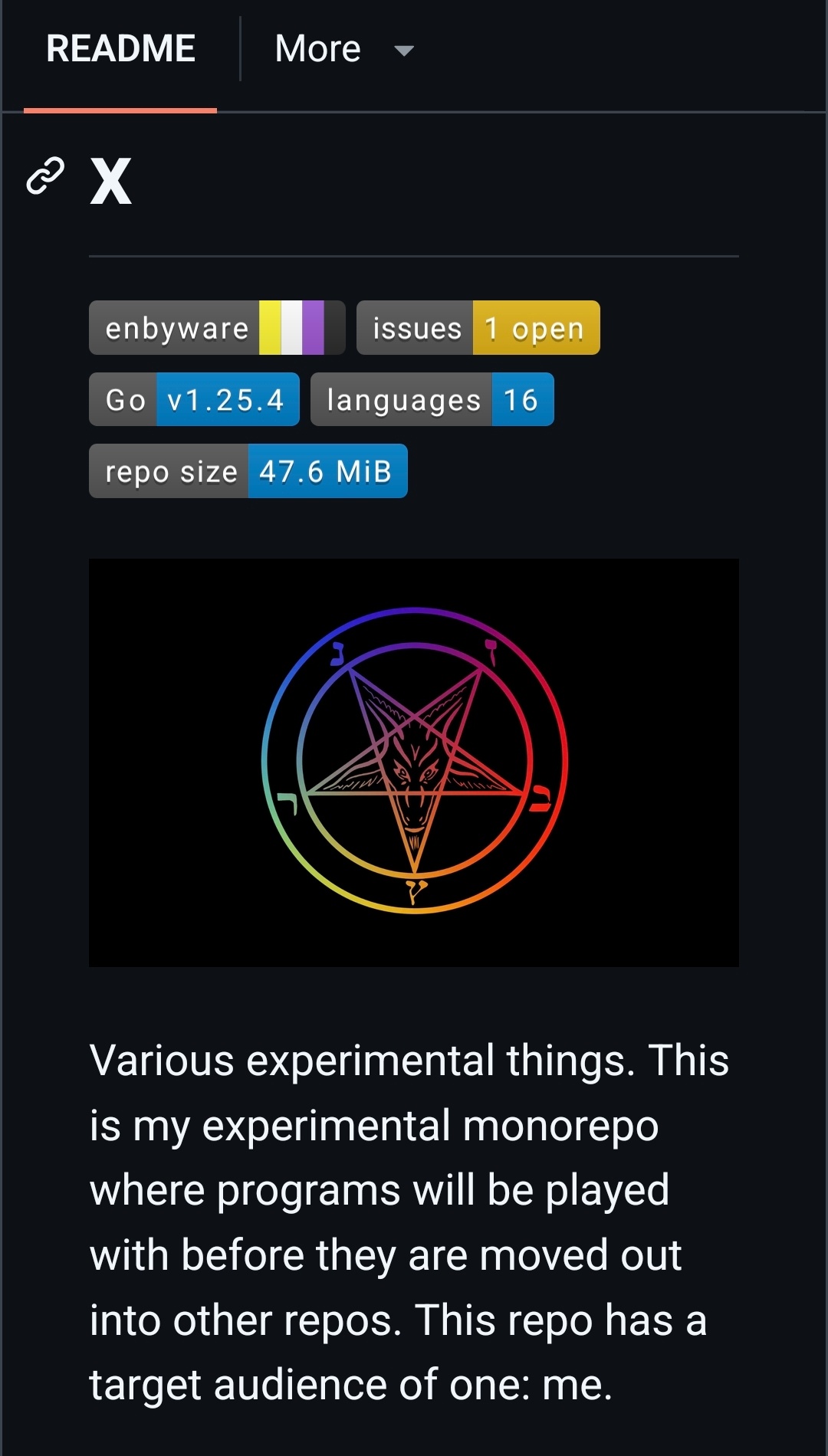
Trochę mnie zaskoczył obrazek na jednym z repozytoriów twórcy firewalla anti-ai - Anubis.
https://github.com/Xe/x/blob/master/.x/baphomet.webp
#github #gownowpis #programowanie
Zaloguj się aby komentować
Ile jest takich co rzeczywiście by wrzucili info w commicie, że byli asystowani przez AI?
Na ile twórcy projektów są obciążeni przez code review pull requestów (nomen omen vibe coderów)?
Czy vibecoding to szansa dla projektów na otrzymanie większego wsparcia od społeczności?
#programowanie #pytanie #github
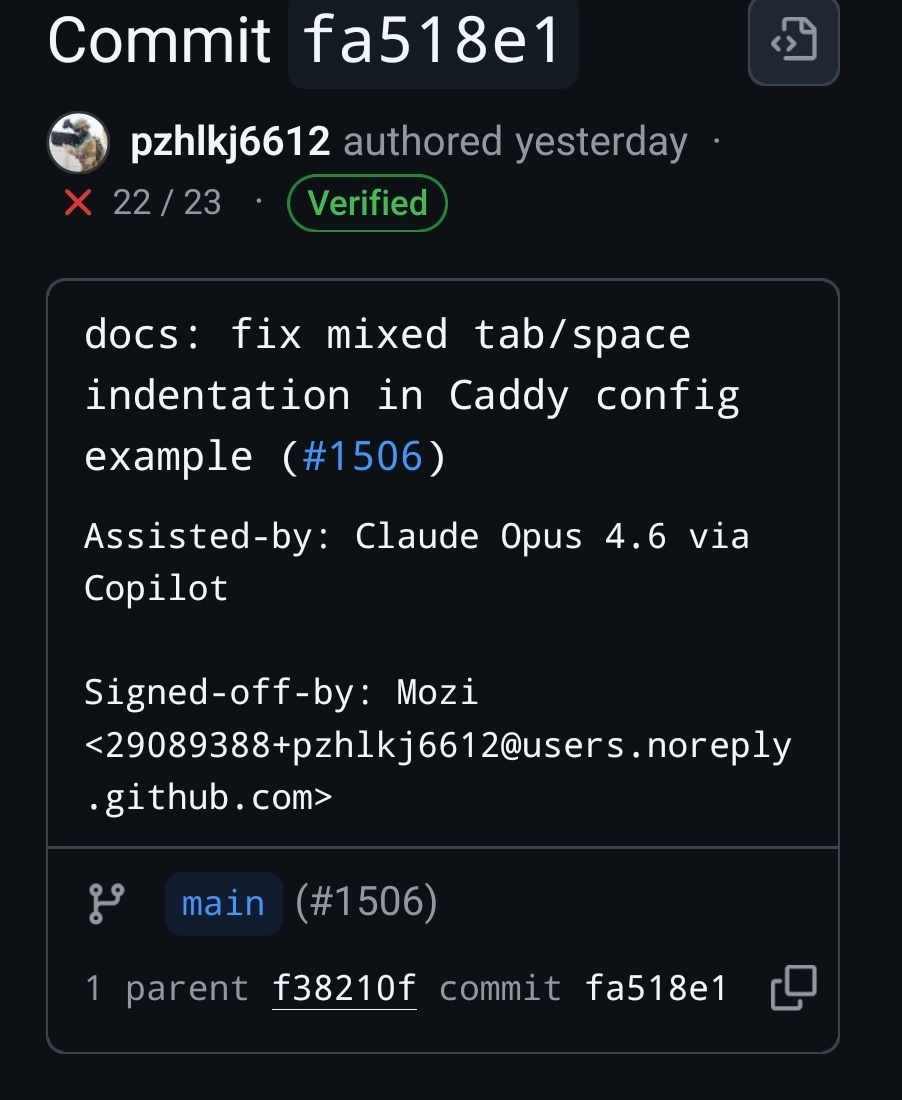
Czasem ten komentarz jest taka oznaka, że publikowany jest niskiej i może zawierać halucynacje większe niż gdyby napisało się ten kod z palca. Nie korzystam z Claude Code, ale czasem sam dopisuję do commita informację, że powstał on przy wsparciu zewnętrznych narzędzi co ma właśnie sugerować, że np. bugfix może aktualnie wprowadzać więcej błędów niż naprawiać. Myślę, że to szczególnie jest zauważalne jak Cursor czy Claude Code pisze dokumentację, albo testy jednostkowe, gdzie ich jakość często jest przeciętna (ale lepsza niż nie istniejąca) - nawet na Opus 4.6.

U mnie ostatnio ziomek robił walidację w libce zod no i zapomniał usunąć komentarz //główny schemat <nazwa_obiektu>

@detex
Czy vibecoding to szansa dla projektów na otrzymanie większego wsparcia od społeczności?
Nie, to jest przekleństwo dla projektów Open Source. Twórcy/opiekuni projektów są zasypywani bezużytecznymi pull requestami i zgłoszeniami nieistniejących bugów już od jakichś 2 lat i z roku na rok jest coraz gorzej.
Zaloguj się aby komentować
Serio? Jeszcze zaraz PornHub zacznie achievmenty dodawać :D
#github #microsoft #cotusieodpierdala


Zaloguj się aby komentować
Zaloguj się aby komentować
#heheszki #humorinformatykow #linux #github #zajebanezfacebooka
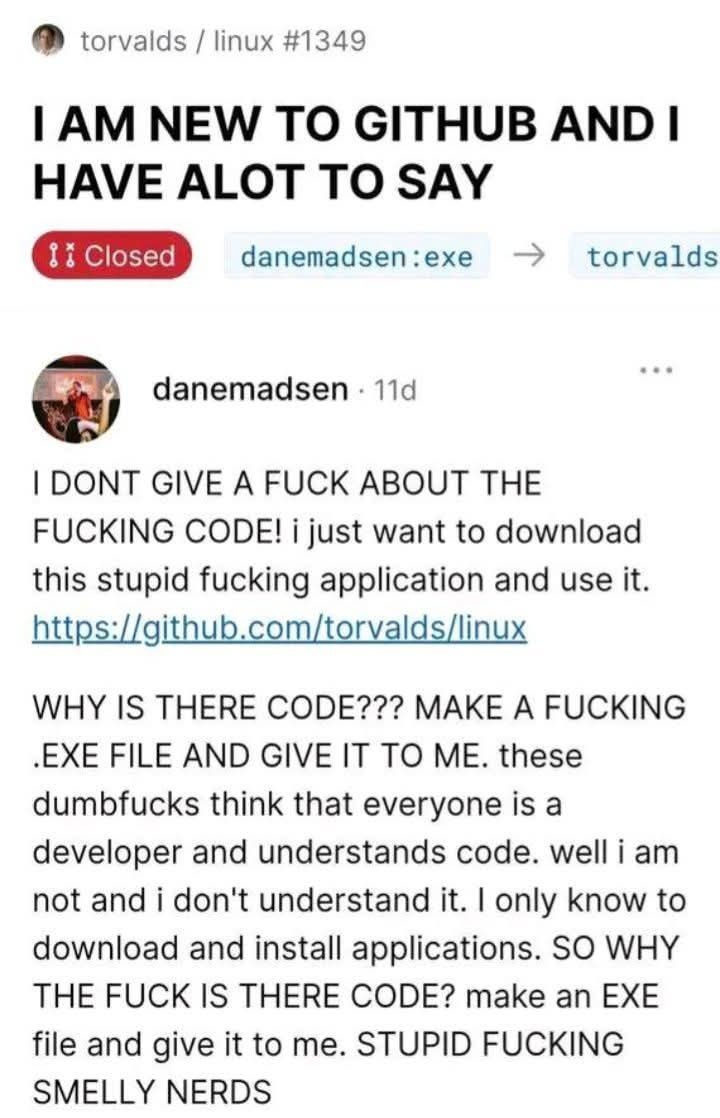

@fadeimageone BTW nie ma co ukrywać, że GitHub jest tak nieczytelny, że jak ktoś wchodzi pierwszy raz na stronę projektu to pierwsze pytanie na forum czy grupie jest zawsze "GDZIE TU JEST PRZYCISK DOWNLOAD!?" xDDD

Jak nie umiesz sobie skompilować programu, to daruj sobie linuxa i wróć do Windowsa, czy tam Maczka. xD

To ten amerykański, szkolny bully, do którego nie dotarło jeszcze, że będzie pracował dla tych nerdów :p
Zaloguj się aby komentować

Znacie, korzystacie, fajna robotę ktos robi https://virtubox.github.io/nginx-ee/
#nginx #linux #opensource #github #vps
No złoto wszystko co potrzeba
Zaloguj się aby komentować

Jakiś czas tego używałem i działało, ktoś tu zrobił regres
Zaloguj się aby komentować

@zboinek na pierwszym miejscu się pojawia

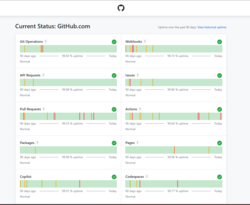
https://www.githubstatus.com/ polecam, w poprzedniej robocie miałem alerty na maila i powiadomienie dźwiękowe jak padło, bo tam trzymaliśmy kod i sporo CI
@zboinek Już śmiga #heheszki
Zaloguj się aby komentować

Codex od OpenAI to AI, które koduje, debuguje i testuje w chmurze. Zintegrowane z GitHub, zmienia programowanie. Czy to rewolucja, czy zagrożenie dla deweloperów?
#technologia #AI #programowanie #programista15k #github
Ejj, ludzie z #programowanie pomóżcie.
Ciągnąc dalej temat interferencji fal znalazłem sposób na symulacje. Ale jest to w postaci gołych plików na #github
https://github.com/0x23/WaveSimulator2D?
Ale mimo podążania za instrukcją nie uruchamia mi się symulacja.
A z #python to ja jestem noga.
PyCharm zainstalowany, ale próba dalszego postępowania zgodnie z instrukcją wyrzuca błąd.



Ehhh, teraz taki problem ma
Traceback (most recent call last):
File "E:\Python\WaveSimulator2D-main\wave_sim2d\examples\example0.py", line 5, in <module>
import cv2
ModuleNotFoundError: No module named 'cv2'
Uwielbiam pythona, uwielbiam kiedy potrzebuje użyć jakiegoś programu i jego jedyna dostępna wersja to taka do ręcznego zainstalowania poprzez sklonowanie repo i doinstalownie zależności przez pip. Kocham kiedy muszę dla każdego programu robić osobne wirtualne środowisko i instalować te same paczki po 15 razy w różnych wersjach. Jeszcze bardziej kocham jak się potem okazuje, że to jest jakaś kosmicznie stara i specyficzna wersja pythona której nawet nie ma skompilowanej dla twojej dystrybucji wiec jeszcze musisz poczekać aż zbuduje ci się cały python lokanlnie u siebie. A na koniec po odpaleniu i tak zobaczysz błąd, że nie udało się zimportować *jakiegoś_gówna.py*.
Taki żart ofc, umiem to wszystko zrobić i dobrze rozumiem dlaczego tak jest ale dobrze wiemy, że każdy choć raz przez to przeszedł xD.

ja pi⁎⁎⁎⁎le, sobie znalazłem zajęcie na drugi dzień świąt
@myoniwy dalej zainteresowany? bo nie wiem czy pisać instrukcję. no i czy masz kartę graficzną wspierającą CUDA?

Zaloguj się aby komentować
#git #linustorvalds #programowanie #github
Two decades of Git: A conversation with creator Linus Torvalds

Gdyby mi ktoś powiedział 16 lat temu, że będzie tak popularny to chyba bym nie uwierzył. Pamiętam jak ja trzymałem programy na studia w git a inni w svnach i cvsach
Zaloguj się aby komentować
400 darmowych aplikacji #windows
#zadarmo #github
https://github.com/Axorax/awesome-free-apps?tab=readme-ov-file#vpn-and-proxy-tools
Zaloguj się aby komentować


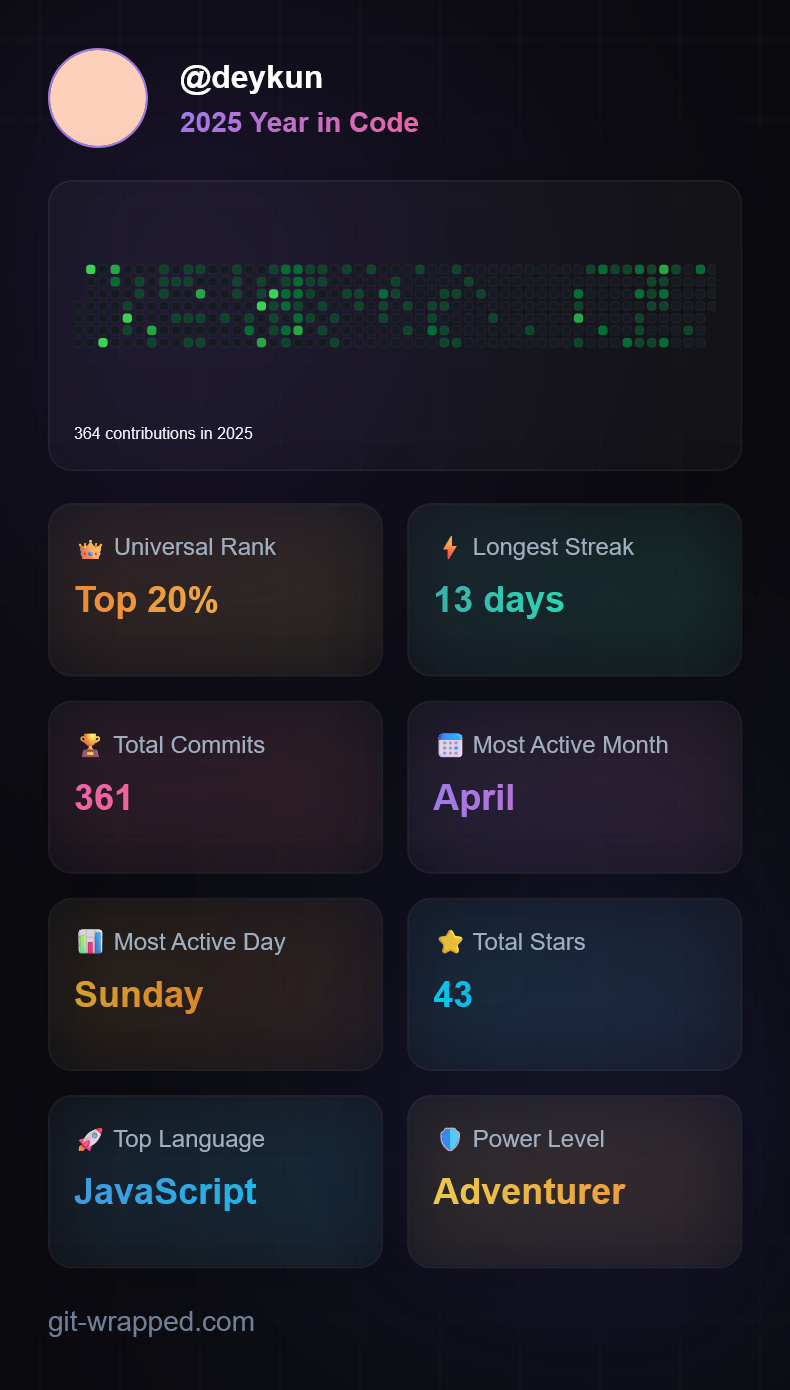
@Deykun - gratulacje w byciu mistrzem JavaScriptu

@koszotorobur a mi smakuje
@Deykun - a czy ja sugerowałem, że nie?
Odniosłem się to tego co jest na screenshocie.
Nie można już nikogo pochwalić by nie myślał, że to sarkazm
Fajne to


@Deykun fajne tylko jak ktoś ma mało aktywności to tak bym powiedział jeszcze bardziej działa na wyobraźnię xd
Zaloguj się aby komentować

Całkiem normalny wywiad z założycielami ESET (m.in.w kontekście ataków ruskich na nasze małe sieci). Wrzucam z 3 powodów:
Python jest obecnie najczęściej używanym językiem w serwisie GitHub!
Sztuczna inteligencja wprowadziła Pythona do czołówki języków programowania w 2024 roku.
Wiąże się to ze wzrostem liczby programistów "data science" oraz "machine learning" na świecie, przez co Python wyprzedził JavaScript jako najpopularniejszy język programowania na GitHubie.
Źródło: https://github.blog/news-insights/octoverse/octoverse-2024/
#programowanie #python #programista15k #sztucznainteligencja #machinelearning #datascience #github
Ja nie uznaje za język coś, gdzie bloki się robi intendami i można pisać bez średników, brrr (╯°□°)╯︵ ┻━┻
@AureliaNova - a ja uznaję tak i tak - przecież i tak kod we wszystkich językach się formatuje wcięciami dla lepszej czytelności
Poza tym przeszedłem przez wszystkie popularne języki programowania i jak trzeba jestem w stanie w nich napisać całkiem skomplikowane rzeczy - bo języki programowania to tylko narzędzia - głupio by było ich nie używać gdy ma to największy sens do danego zadania
@koszotorobur ja wiem, tylko sobie śmieszkuję. Na pewno kwestia przyzwyczajenia.
Ale moment, gdy mi apka nie chciała się kompilować, bo miałem niespójne wcięcia i musiałem w kilkunastu plikach zamieniać spacje na tab, ostatecznie przekreslił go w moich oczach :P
No i bomba, bo to świetny język, a popularność nadaje trakcji rozwojowi, bo i pieniążki się znajdują dla fundacji. Jest starszy niż Java, a wiele osób myśli, że to świeży język, bo długo był w cieniu.

@lurker_z_internetu pewnie ci sami zoomerzy co nie wiedzą co to system plików.
https://www.theverge.com/22684730/students-file-folder-directory-structure-education-gen-z

@Opornik ci sami zoomerzy co dupią fleka "bardzo wolno mi się wszystko wczytuje, a ten komputer/telefon nawet roku nie ma" ( ͡~ ͜ʖ ͡°)
@koszotorobur A jakie duże aplikacje webowe/desktopowe sa napisane w Pythonie? Serio pytam, bo jak wieki temu wybierałem technologie pod jakieś mikroserwisy to Python może i był najwolniejszy, ale za to nie dało się go utrzymać in the long run. Może coś się zmieniło
@Orzech - tylko największe aplikacje dostępne w sieci: https://insights.daffodilsw.com/blog/top-10-applications-built-using-python
Poza tym w korpo Python niesamowicie też urósł do pełnoprawnego języka i w moich 3 ostatnich korpo (wliczając obecne) Pyhon jest używany do:
Napisania mega skomplikowanych prezentacji danych w formacie strony internetowej używając modułu Dash od firmy Plotly
Obróbki danych typu ETL używając modułów jak Pandas oraz Polars
Automatyzacji zbierania i obróbki danych potrzebnych do generowania raportów typu "security compliance" z wewnętrznych serwerów oraz różnych dostawców chmurowych
Budowania modeli finansowych używając uczenia maszynowego
Automatyzacji zadań administratora systemów przy pomocy Ansible
Tworzenia infrastruktury chmurowej z kodu (Infrastructure as a Service) używając Pulumi
@koszotorobur No z tych wymienionych w artykule to w większości jest to przekłamanie - chociazby w FB, Netflixie i innych backend nie jest napisany w Pythonie, jest to głównie tooling, rzeczy dookoła głównego codebaseu, który jest w C++, Javie, Go I podobnych. W Uberze przepisują Pythona na Go. Spotify jest napisane w Javie. Możesz mi uwierzyć, że YouTube nie jest napisany w Pythonie
Z tych wymienionych w artykule chyba tylko Instagram jest napisany w Pythonie, ale Meta ma swojego forka Pythona który jest kilka razy szybszy od zwykłego.
Zaloguj się aby komentować
Stworzyłem projekt, który wyświetla listę serwerów CS2D, zbudowany w Node.js przy użyciu Fastify. Oto najnowsze zmiany:
Zaktualizowany interfejs UI dla lepszego doświadczenia użytkownika
Dodano opisy do dokumentacji API
Wprowadzono nową stronę statystyk
Optymalizacja kodu dla lepszej wydajności
Zintegrowano Highlight.js dla lepszego podświetlania składni
Sprawdź to tutaj: https://cs2d-serverlist.erpa.cc/
Zobacz kod na GitHubie: https://github.com/ernestpasnik/cs2d-serverlist
Dajcie znać, co myślicie!
BTW Fastify > Express.js
#nodejs #javascript #opensource #github #programowanie #javascript #fastify

@Hajt Ładne
Zaloguj się aby komentować

















/cdn.vox-cdn.com/uploads/chorus_asset/file/22864733/VRG_ILLO_4756_Student_Professor_Folders_Lede.jpg)
