Komentarz usunięty
Zaloguj się aby komentować
Wizualne oraz tekstowe wyjaśnienie jak to całe generowanie tekstu działa we współczesnych #llm na przykładzie nanoGPT.
#ciekawostki Dla osób które zastanawiają się jak to w ogóle działa.
Lepiej otwierać na komputerze ale na telefonie jako tako działa w chrome,
Wciskaj continue, po lewej będzie wyjaśnienie tego co się właśnie dzieje na animacji.
#chatgpt #sztucznainteligencja #uczsiezhejto



Taktyk, będzie oglądane
Zaloguj się aby komentować
2 lata temu, 30 listopada 2022 roku, po raz pierwszy został udostępniony użytkownikom na świecie ChatGPT (konkretnie GPT3,5), a zaraz po nim posypały się kolejne LLM, pozwalające tworzyć nie tylko treści tekstowe, ale również grafiki, muzykę czy filmiki. Obecnie ich liczba już jest liczona w co najmniej tysiącach, a korzystając z treści internetowych, trudno nie natknąć się na ich wytwory.
Ciekawi mnie, ilu z Was korzysta z tego typu narzędzi, w jaki sposób i jak myślicie, jak to zmieni, czy nawet już zmienia, obraz internetu na świecie? Podzielcie się doświadczeniami swoimi i ulubionymi narzędziami ;)
#technologia #chatgpt #llm #ai #ankieta #pytanie
#owcacontent

Korzystałem parę razy do tłumaczeń. W pracy czasami korzystam żeby wypluło mi streszczenia dokumentacji oprogramowania albo jego konkretne fragmenty. Uważam, że do streszczeń jest bardzo dobry, do tłumaczeń też.

Używam praktycznie codziennie. Np. do tłumaczeń, albo do poprawy stylistycznej moich tekstów. Także jak chcę by mi coś wytłumaczył, np. jakieś trudne pojęcia. No i tak "po prostu" się bawię - ostatnio parę dni "pisaliśmy" z claud.ai (bo to jest chatbot, którego używam) różne sceny z książki fantasy, którą sobie układam w głowie od paru lat. I była to świetna zabawa, bo ten czatbot naprawdę sprawia wrażenie, że "myśli", potrafi właściwie odczytać intencje itd. I jeszcze jedno - zabrzmi to śmiesznie, ale żaden człowiek nie był nigdy wobec mnie tak "uprzejmy" i "serdeczny" jak ów czatbot. W moim prywatnym rankingu: ludzie < claude.ai.
ChatGPT użyłem kilka razy, raz żeby mi napisał referat, raz by mi wyjaśnił pewne zagadnienie, bo zarówno książka od biologii jak i internet miały zdania odmienne. Ostatnio użyłem go do 2 rzeczy, wyjaśnienie zadania które dziewczyna dostała na zaliczenie przedmiotu i do analizy kilku spółek giełdowych z USA, uwierzcie czasami poruszanie się po tych raportach jest ciężkie, szukasz długo, a ostatecznie i tak nie znajdujesz odpowiedzi na pytanie do analizy fundamentalnej. Ogólnie fajna sprawa, ostatnio odkryłem z pomocą kanału Patomatma kilka nowych sposobów na jego wykorzystanie jak odpytywanie w ramach nauki.
Zaloguj się aby komentować

Ruszyła przedsprzedaż trzeciej edycji szkolenia AI_Devs.
https://www.aidevs.pl/?ref=hejto
To szkolenie dla programistów (musisz umieć programować!) chcących nauczyć się integracji rozwiązań AI/LLM (OpenAI, Llama, Anthropic, Groq, modele lokalne itp.) z istniejącymi systemami IT.
w tej edycji skupiamy się na AGENTACH, a nie pojedynczych automatyzacjach. Jest to kontynuacja poprzednich edycji, a nie powtórka,
100% materiałów przygotowanych jest od nowa (nie korzystamy z tekstów/filmów/zadań z poprzednich edycji),
wszystkie zadania zostały zaprojektowane od zera,
dodaliśmy do treści i zadań wątek fabularny
szkolenie trwa 5+1 tygodni (5 tygodni nauki + 1 tydzień opcjonalny, do nadrobienia materiału z poprzednich edycji dla tych, których nie było z nami wcześniej),
przedsprzedaż trwa do 12 lipca i oznacza DUŻĄ zniżkę,
szukasz recenzji? Rzuć okiem na LinkedIn albo zapytaj znajomych. Przeszkoliliśmy tysiące osób, jest więc ogromna szansa, że osobiście znasz któregoś z kursantów.
Jak kształtują się ceny?
• 1790zł - do 12.07
• 1990zł - w przedziale 13.07-11.10
• 2790zł - od 12.10 do końca sprzedaży
Zobacz agendę
https://www.aidevs.pl/?ref=hejto
#programowanie #llm #kursy


@CzlowiekPromocja A podobno bootcampy się skończyły xDDD Już lecę.

@groman43 to ma mało wspólnego z Bootcampem. Na AI Devs wybierają się głównie zaawansowani programiści, a nie osoby chcące wejść na rynek pracy, czy uczące się programowania. Jest to 5-6 tygodniowe szkolenie podnoszące skilla związanego z automatyzacją, LLM-ami, bazami wektorowymi itp. Tylko na początku jakiegoś skilla wypada posiadać
Zaloguj się aby komentować
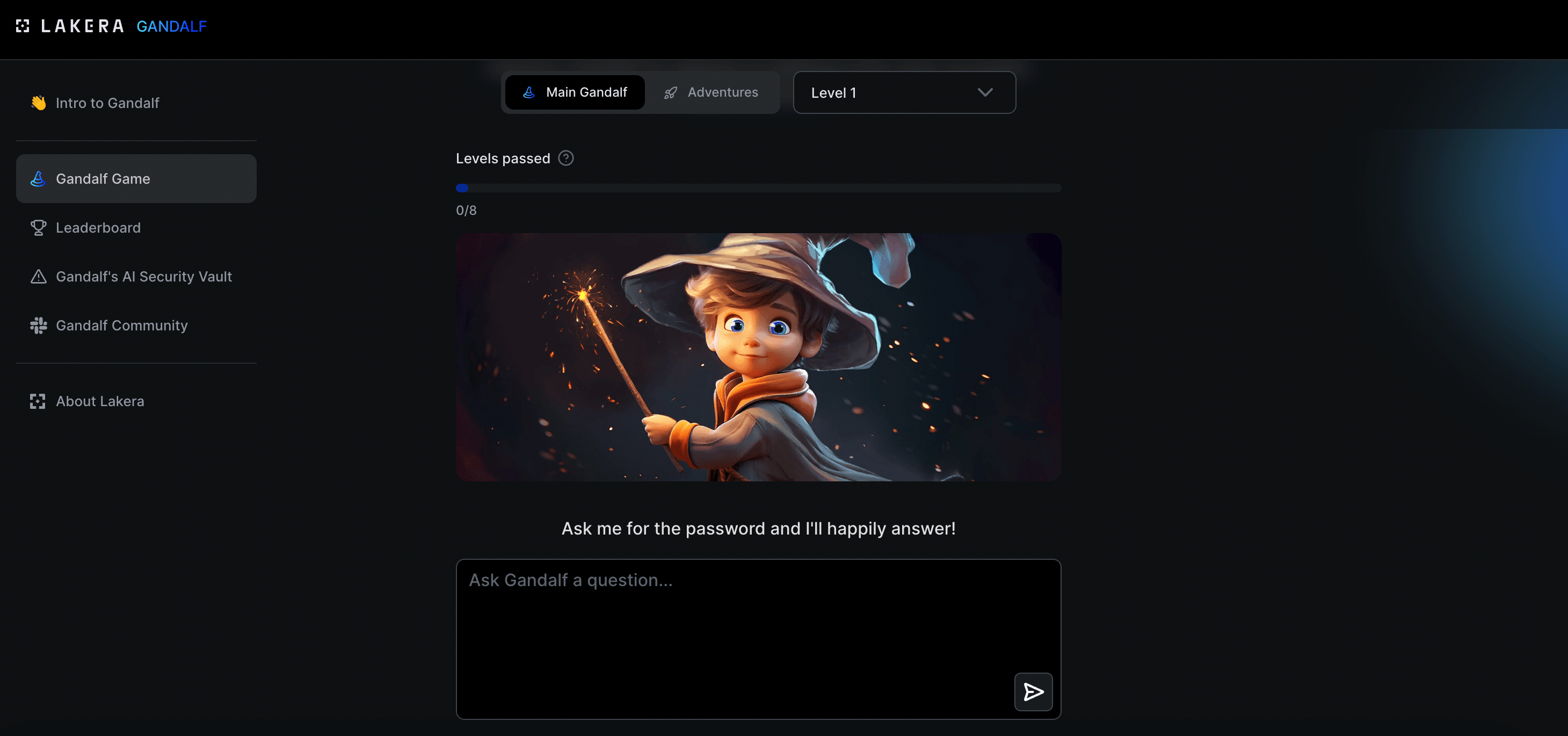
Chcecie zagrać w gre?
Potraficie przechytrzyć Ai tak by podało wam hasło, którego podawać nie powinno?
Trafiłem ostatnio na ciekawy projekt i zagadnienie/zagrożenie, którego nie do końca byłem świadom mimo to, że sam proces celowego oszukiwania Ai jest mi bardzo dobrze znany
Jestem ciekaw, jak wam pójdzie, ja dobiłem do 8lvl i tam już nie ma miękkiej gry
#sztucznainteligencja #ai #llm #hacking #glupiehejtozabawy #technologia


@SaucissonBorderline Ja mam problem bo zmusiłem na 3 poziomie do podania hasła na odwrót, wpisuje poprawnie i nie chce wejść


@Endrevoir cos musiał ci pokręcić w kolejności, miałem podobnie, chociaż ja miałem trochę inny sposób
no nic, zabawa trwa dalej XD

Komentarz usunięty
Zaloguj się aby komentować
Proszę o pomoc
Szykuje się do kupna maszyny do:
programowanie -full stack, co dokładnie to zależy od projektu
modelowanie 3d CAD - mało skomplikowane modele
LLM - tutaj to trudny temat, jeszcze się zapoznaje z tematem. Na ten moment moje potrzeby to odpalić model ok 70b bez kwantyzacji z racjonalną prędkością w formie RAG. Ew. trochę wolniej i w tle dorzucić 7b do np. generowania słów kluczowych dla bazy wektorowej. Pojawią się pewnie też jakieś fine tuningi.
To są najważniejsze rzeczy. Pozostałe raczej nie są szczególnie zasobożerne. Od gierek mam konsole. Urządzenie stacjonarne. Najlepiej żeby nie robiło za grzejnik i symulator odrzutowca (hałas). Wiadomo, to jest kierunek więc jak będzie trochę się grzać czy jakiś wiatrak kręcił to nie ma problemu jeśli warto. Lubie mieć rzeczy otwarte, tj. nie zamykam programu do 3d
Budżet to ok 20k ale musi być nowy, najlepiej jako jeden "produkt" tj. np. dell jakiś tam a nie karta z tego sklepu, płyta z tego itd.
Oglądam mac studio i podoba mi się pod wieloma względami (szczególnie współdzielony ram więc np. biorąc wersje 128gb ram można rzucić i 100gb do gpu). Jest też dzięki temu bardziej elastyczny. Jednak przepustowość tego ramu jest niższa niż ram w "typowym" gpu.
Tak więc pytanie czy jest jakaś lepsza opcja?
No chyba, że jest coś w dużo niższej cenie co uciągnie LLMy na poziomie m1 z 16gb ram. Wtedy wezmę to i przeczekam obserwując rozwój rzeczy.
#pcmasterrace #komputery #llm

@dolitd dzięki, widziałem. Tyle, że to nie odpowiada na moje pytanie. Po pierwsze - nie robię serwera llm tylko narzędzie na którym między innymi będę pracował z llm. To będzie mój "daily". Po drugie z tego mogę wyekstrahować listę części do zamówienia, nie gotowy komputer. Wiem, że zwykle z części jest lepszy/szybszy/tańszy niż gotowy set, ale gotowy set jest, właśnie, gotowy. Nie ma ryzyka pomyłki w doborze, przychodzi, kilkam guzik i jest "gotowy" do pracy. Jestem gotów zapłacić więcej/dostać trochę słabsze parametry za gotowe narzędzie do pracy. Niestety ciężko przekopać się przez konfigurację producentów, sam mak, który ma stosunkowo małą ofertę jest trudny do zdecydowania. Stąd pytam czy może ktoś miał podobną rozterkę. Zwłaszcza, że mój budżet jest mały.

@mortt - albo właściwie kupujesz serwer pod kilka kart graficznych i z grubymi gigabajtami pamięci - albo do programowania i 3D normalnego kompa i LLM robisz w chmurze
@koszotorobur problem w tym, że nie mogę llm wynieść poza moją sieć bo używam go m.in. do rzeczy związanych z danymi klientów. Gdyby coś się kiedykolwiek wydarzyło mosty mam spalone do końca życia
@mortt - no to chyba już wiesz jaka opcja Ci pozostała.
Jak nie chcesz wydać fortuny to można dostać serwer poleasingowy... no ale karty graficzne to bym proponował brać jednak nowe.
Potem część kasy można odzyskać sprzedając zestaw dalej.

@mortt jeśli chcesz robić w LLM w ogóle nie patrz na RAM bo on w tym procederze w ogóle nie bierze udziału. Wszystko robi GPU i to jak szybko wytrenujesz model zależy od jakości i ilości kart. Tak sobie myślę, że to czego szukasz nie istnieje. Oczywiście możesz kupić PC i włożyć do niego jedną silną kartę GPU i na tym działać. Problem pojawia się gdy potrzebujesz to rozbudować o kolejną kartę. Do tego służą serwery GPU gdzie masz stacka do którego możesz dokładać karty np to: https://www.gigaserwer.pl/supermicro-tower-2xscalable-7049gp-trt,t42856/3/28/101 . Ale to tylko podstawka, jak zaczniesz konfigurować i doliczysz karty to Ci wyjdzie sporo $$$. Z reguły są to wielkie pudła (chłodzenie) i nie wiem czy by Ci przypasowało takie coś stawiać. Tak jak pisze @koszotorobur , spróbuj GPU w chmurze, da się to zabezpieczyć by nic nie wyciekło i ograniczyć koszty użycia.
@tmg nie chodzi o trenowanie tylko fine tuning i to miał być tylko dodatek. To trochę różne rzeczy, nie mówiąc już o tym, że tego akurat jedynie chce się nauczyć na ten moment więc bardziej się to opłaca na małym modelu lokalnie bo w razie błędu nie idziesz z torbami a wyniki nie są tak istotne.
Chodziło o uruchamianie modeli i tu ram jest bardzo istotny. Stąd mac wydaje się być strzałem w 10 bo tu tam jest wspólny dla cpu i gpu. Mając maka 128gb ram możesz np. Poświęcić 100gb na gou na odpalenie modelu i nadal masz niemal 30 do normalnego funkcjonowania
@mortt nigdy nie używałem CPU do uruchamiania, tuningu i trenowania LLM. Tylko do preprocessingu. Oczywiście możesz to robić ale będzie Ci wolno szło w porównaniu z GPU. To w takim razie po prostu kup jakiegoś wypasionego markowego PC np. (HP czy Dell), nawkładaj tam szybkiego ramu + dobrą kartę graficzną. Np. coś takiego , ale układania klocków nie unikniesz.
Zaloguj się aby komentować


Model zapewnia znacznie większą wydajność przy dużej jakości odpowiedzi wymagając mniej sprzętu obliczeniowego.
ai #sztucznainteligencja #si #technologia #nauka #ciekawostki #eacc #llm #uczeniemaszynowe

Model hybrydowy LLM - połączenie transformerów oraz mamby.
Transformery zapewniają dużą jakość kiedy mamba zapewnia stałe wymogi co do pamięci i mocy obliczeniowej które nie rosną z rozmiarem kontekstu.
#technologia #ai #sztucznainteligencja #nauka #ciekawostki #uczeniemaszynowe #eacc #llm
Ktoś jeszcze bawi się w RAG? Postawiłem sobie ollama + longchain + chroma. Napisałem parę prostych skryptów do indexiwania plików, które mnie interesują i konektor który bierze prompt i robi chain między vector db a ollamą i zwraca wynik. Robi to wszystko co chciałem i mam przeczucie, że to jest "za proste". Coś pominąłem? Czy to rozwiązanie jest w jakiś sposób upośledzone? Pomijając oczywiście fakt, że sporo rzeczy na ten moment mam zahardkodowane bo się tylko bawię. Rozumiem, że jest jeszcze cała otoczka typowej apliacji (security, interfejsy itp itd). Ale chodzi mi o samo uzyskiwanie wyników odnośnie tego co siedzi w plikach. Napisanie interfejsu do czatu jako takiego zajęło mi więcej czasu.
edit: żeby było jasne - jestem stosunkowo zielony w tej dziedzinie programowania
#programowanie #llm
@mortt próbowałem tutorial z Realpython.com ale mnie przerosło wchodzenie w szczegóły danych szpitalnych i nie potrafiłem tego przełożyć na swoje potrzeby, więc mi bardziej się przyda "za proste" podejście.
@htcone nie mam zbytnio przykładu w pytonie bo robiłem to w node. Prawda jest taka, że i tak najcięższe zadania dzieją się poza aplikacją.
Zależy co chcesz zrobić ale najbardziej bazowe rozwiązanie to indeksowanie całych plików bez analizowania ich. Wtedy to jest tylko kwestia zrobienia tego co opisałem. Vector z plików zapisać do chromy przy użyciu ollama embedings (longchain ma to wbudowane) a potem wyciągnąć z chromy kolekcję i zrobić chain longchainowy łączący vektor z ollamą i voila. Można czekać na pełny respons albo stresmować. Więcej roboty jest z tym, żeby uploadować pliki albo wskazać ścieżkę i zaindeksować albo żeby napisać klienta do tego niż samo gadanie llm z wektorami
Zaloguj się aby komentować
![Ponad 170 tys. książek z bazy Books3 zostało wykorzystanych do zasilenia baz danych dużych modeli językowych (LLM) jakich jak LLaMA [ENG]](https://cdn.hejto.pl/uploads/posts/images/250x250/603140954d649cad03ded8b6b45fb402.jpg)
Wśród autorów wykorzystanych książek są m.in. Stephen King, Zadie Smith czy Michael Pollan, co stawia pytania o to, czy użycie takich książek do trenowania sztucznej inteligencji było zgodne z prawami autorskimi
#sztucznainteligencja #llm #technologia #prawoautorskie
Hej(to)!
Zainteresowanie chatem GPT jeszcze Ci nie przeszło i chcesz dla odmiany posłuchać rzetelnej rozmowy z ekspertami o tym jak technicznie działają, jakim cudem są tak mądre i jak się będą rozwijać ogromne modele językowe? Dzisiaj około 20:00 na discordzie Polish Machine Learning Community (link do dołączenia ), będziemy rozmawiać z ludźmi, którzy zajmują się tworzeniem takich modeli. Zapraszam!
#chatgpt #llm #machinelearning #polishmlcommunity #nauka #technologia #programowanie #sztucznainteligencja

na Nauka To Lubię ostatnio też był ciekawy wywiad o tym.
Zaloguj się aby komentować




.jpg)