Tomasz Hajto 15 lutego 2007 roku, po rozprawieniu się ze starszą panią na pasach
#hajto #tomaszhajto #humorobrazkowy #memy



look997 | Przemyślenia, kwestie społeczne, polityka, śmieszki, anegdoty. Również technologia, webDev, AI, nauka.
Tomasz Hajto 15 lutego 2007 roku, po rozprawieniu się ze starszą panią na pasach
#hajto #tomaszhajto #humorobrazkowy #memy
Zaloguj się aby komentować
Co to k⁎⁎wa ma być?
https://www.youtube.com/@SoAreWeFamous
Jakaś podejrzana relacja murzyna i dziewczynki.
Na okładce kanału takie foto...
Na insta mi wyskoczyli i widzę że dziwne, i jeszcze kanał na YT mają.
Widać że raczej dość świeże media mają.
To trzeba gdzieś pozgłaszać?
#murzyn #liczeniemurzynow #wielkieliczeniemurzynow #youtube #pedo #grooming #alarm

Na Insta też są, całość śmierdzi, ludzie w komentarzach też nie wyglądają na spokojnych o taką relację.
Mnie to wręcz wkurwia, bo na żywca się dokonuje jakaś krzywda albo trauma na dziecku prawdopodobnie.

Spojrzałem na miniatury i tytuły filmików i potwierdzam - tak - jakaś patologia. Jak zresztą cała ta część jutuby.
Zaloguj się aby komentować
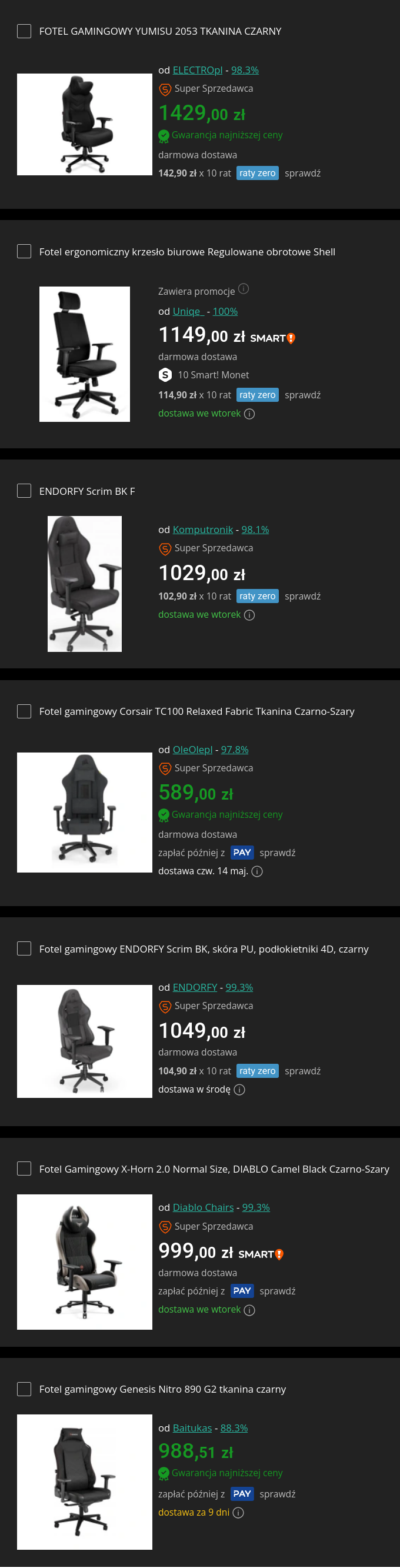
Ta lista jest prawidłowa czy jakieś głupoty? Jakie alternatywy?
Kryteria to: opinie, jakość, trwałość, wygoda, nie skrzypienie, stabilność (że się nie rozklekotają że wszystko lata i dryga).
Nie oceniaj ceny do jakości tylko te cechy same w sobie.
Wszystkie są tkaninowe, żaden nie jest siatkowy, a ENDORFY Scrim BK jest tkanina i skóra PU.
Ranking 7 foteli gamingowych — wersja ostateczna Zweryfikowana przez Claude, Gemini, ChatGPT i Grok. Kryteria: opinie, jakość, trwałość, wygoda, brak skrzypienia, stabilność.
4. ENDORFY Scrim BK F
5. Genesis Nitro 890 G2 tkanina czarny
6. ENDORFY Scrim BK
7. Diablo X-Horn 2.0 Normal Size Camel Black
#fotel #zakupy #gamemasterrace #komputer #sprzetkomputerowy

@fewtoast mam Yumisu od 5-6 lat, materiał puścił na szwach w 1 miejscu, a siedzisko nie jest już tak wygodne, jak kiedyś, ale jak za tysiaka, którego za niego dałem w promocji, raczej śmiało bym go kupił jeszcze raz.

@fewtoast ehhh powiem tak- kupiłem sobie lat może 8, może 10 temu fotel. Clutch Chairz. Niekoniecznie że "musi być gejmingowy" ale taki żeby był solidny i wygodny, bo do tamtej pory siedziałem na tych dość charakterystycznych szmaciakach z centymetrem gąbki pamiętających czasy szkolne (nie pytaj). Na początku- super i za⁎⁎⁎⁎ście. Solidny, stalowa podstawa i duże kółka, nie ma luzów, nic nie goni, siedzi się wygodnie, regulacje podłokietników, można się w całości odchylić do tyłu, zablokować pozycję, do tego skóra z domieszką sztucznej skóry, memory foam, regulowane ergo poduszki pod lędźwia i za kark- no słowem bajer, tym większy, że przechodziłem z czegoś, na czym się wysiedzieć wygodnie nawet godziny nie dało.
Co mogę po tych cca 10 latach powiedzieć. Jeśli chodzi o samą konstrukcje fotela- jedyne czego mi do pełni szczęścia brakuje, to takie odchylane na boki podłokietniki, żebym sobie mógł na tym krześle usiąść po turecku. No tylko że nawet gdyby to nie mogę, bo sam fotel ma podstawę też zbudowaną jak fotel kubełkowy z wygięciami do góry z boków, czego totalnie nie rozumiem poza bajerem.
A poza tym? No cóż- jak go kupowałem, to byłem absolutnie chory na wszelkie formy szmacianych krzesło-foteli z gąbką w środku, bo pamiętając te z czasów szkolnych, to szmata się w nich w końcu przecierała i ta ugnieciona i sparciała gąbka wysypywała. Raz z tatą 1 postanowiliśmy naprawić, jebaniny z tym było więcej, niż to było warte, mimo że efekt końcowy był "jak nówka" i to bez przesady. No ale do brzegu. Z racji tego jak już kupowałem fotel, to stwierdziłem "niee no, ino skóra, z tym się nic nie dzieje". No... i się nie działo. Przez pierwsze 2 lata. Potem ta sztuczna świnia zaczęła powolutku pękać. Rok później się łuszczyć malutkimi płatkami i tak się łuszczy do teraz, coraz bardziej odłażąc tymi płatkami, bo oczywiście ozdobniki musiały być. Normalna skóra przetrwała jakieś 4 lata, potem zaczęła twardnieć, pękać i się odłamywać kawałkami, nieważne że od początku kupiłem sobie środki do ochrony skóry. Pianka formowana na zimno co to miała być nie do zdarcia taka była też jakoś przez 4 lata, a potem siedzenie na fotelu zrobiło swoje. I to nie tak, że nie wiem, coś wystaje, w d⁎⁎ę się wbija czy uwiera, nieee, dalej jest wygodnie, ale no czuć, że już nie jest taka przyjemnie sprężysta jak na początku. Wszystkie mechanizmy, tłok, dźwignie i nawet podłokietniki nadal działają bez zarzutów i paradoksalnie najmniej zniszczony jest... zagłówek.
Czy bym go kupił ponownie? Szczerze.... nie. To nie jest zły fotel, dalej jest wygodny i dalej się trzyma, ale już od 2 lat trzymam na siedzisku jakąś szmatę, żeby te odstające twarde kawałki skóry mi nie rozerwały spodni, bo skóra po utwardzeniu i pęknięciu zrobiła się tak ostra. Te wstawki ze sztucznej świni ciągle się łuszczą, więc istnieje niezerowa szansa, że jak wstanę, to tył koszuli będę miał obrany w tym gównie i będę tym potem siał po domu. Z racji budowy nie ma c⁎⁎ja, że w domu to po prostu wymienię, tak jak to było z tym starym krzesłem, a wysłanie tego do tapicera, zakładając że w ogóle znalazłby się taki, który by się podjął rozprucia tego do gołej ramy, wymienienia pianki i całej skóry na nową (xD), mija się z celem i zapewne kosztami. No i szybko dochodzę do punktu, gdzie następny fotel- jak już go będę kupował- to możliwe, że będzie to jakiś szmaciak, albo siatka na ramie takiego "gejmingowego" tylko z płaskim siedziskiem, albo wydam górę siana i pójdę w full ergo, tylko problem z tymi ergo jest taki, że 90% z nich to są takie "j⁎⁎ak teoretyk"- są tak bardzo "ergo", że wyrzucają całkowicie poza nawias człowieka i luźną wygodę siedzenia i każą ci siedzieć w jednej nieruchomej pozie non stop, nie pozwalając na żadne faktycznie wygodne umoszczenie się. A ja tak wysiedzieć w życiu nie wysiedzę, bo jak robię coś dłużej przed komputerem, to lubię się wyciągnąć, albo poskręcać na tym fotelu, a nie siedzieć kilka godzin jak pierdolony manekin z tego obrazka, bo to z człowiekiem ma mało coś wspólnego.
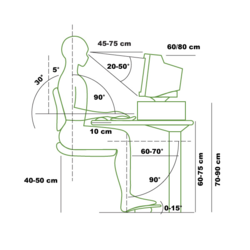

@fewtoast Chodzą słuchy ze te gamingowe zabawki to marketingowy szrot.
Idź do kilku sklepów fotelami, wysiedź wszystkie, może coś podpasuje. Sam tak zrobiłem, wziąłem ten najwygodniejszy. Poszło ponad 1000zł. Było warto? Nie jestem pewien, z czasem okazało się że wcale taki wygodny nie jest. Podejrzewam że efekt "wygodnego pierwszego siedzenia" nie oznacza wygody na długie godziny.
Zaloguj się aby komentować
Boję się jak pies wyskakuje do płota, który jest tuż przy drodze, chciałbym żeby pies nie mógł przebywać tak blisko, niezależnie czy jest za płotem.
Propozycja prawa:
Pies nie może przebywać ileś metrów od drogi, niezależnie od płota, więc musi istnieć albo dodatkowy płot dzięki któremu pies nie podejdzie do drogi bliżej niż na kilka metrów, albo po prostu główny płot działki musi być kilka metrów od drogi, jeśli przebywa za nim pies.
Wtedy łatwo będzie móc ocenić i karać właściciela, gdyby puszczał psa bliżej, nie byłoby żadnej uznaniowości.
Art. X. Zabezpieczenie posesji przylegających do dróg publicznych
Właściciel lub opiekun psa na posesji graniczącej bezpośrednio z drogą publiczną, chodnikiem lub ciągiem pieszo-jezdnym, zobowiązany jest do utrzymywania zwierzęcia w sposób uniemożliwiający mu bezpośredni kontakt z granicą posesji od strony tej drogi.
W celu realizacji obowiązku, o którym mowa w ust. 1, właściciel zobowiązany jest do wyznaczenia wewnętrznej strefy bytowej psa, oddzielonej od zewnętrznego ogrodzenia posesji stałą barierą fizyczną (np. dodatkowym wygrodzeniem) w odległości nie mniejszej niż 2 metry od granicy działki.
Obowiązek ten dotyczy wszystkich psów, bez względu na rasę, wielkość i przejawiany stopień agresji.
Dopuszcza się odstępstwo od stosowania bariery odległościowej wyłącznie w przypadku zastosowania pełnego ogrodzenia (muru lub ekranu) o wysokości min. 2 metrów, całkowicie uniemożliwiającego kontakt wzrokowy i akustyczny zwierzęcia z osobami trzecimi na drodze, o ile konstrukcja ta zapewnia pełne bezpieczeństwo fizyczne.
#psy #psiecko #bezpieczenstwo #polskiedrogi #prawo


Jakiemu realnemu zagrożeniu ma to zapobiec?

Pojebało w kitę? 2m? Może 100km? Wystarczy bariera taka, aby uniemożliwić fizyczne przekroczenie jakiejkolwiek części działa zwierzęcia poza zewnętrzny płot. I kara za wkurwianie zwierzęcia i pchanie paluchów lub innych rzeczy poza linię płotu z zewnątrz.
Te 2m to tak z d⁎⁎y wyciągnąłeś że chyba masz jakąś traumę przez własną głupotę spowodowaną, a nie zwierzęta na cudzych działkach.

@fewtoast jeśli się pies rzuca na płot jak psychol to problem raczej z włascicielem a nie z psem lub plotem.
Cały zresztą post opobota to radykalizujący i polaryzujacu belkot....
Post śmierdzi na kilometr sztuczną troską.
Sama idea psa poniekąd polega na tym że szczeka i broni posesji.
@HmmJakiWybracNick kwestia zakazu korzystania ze swojej wlasnej posesji w ramach jej granic jest totalnie iracjonalna.
Prędzej powinnien być ogólnokrajowy mechanizm zgłaszania agresywnych zwierząt co skutkowało by interwencją wobec właściciela.
Zaloguj się aby komentować
Tampon to ass.
Zaloguj się aby komentować
Mogliśmy mieć po 2 złote za litr...
#polityka #orlen #cpn #iran

@fewtoast ja chcę po 50 groszy za litr- kto na mnie zagłosuje?

wystarczyło wprowadzić wolny rynek

W Rosji diesel kosztuje teraz 3,89 zł (w Krasnojarsku). Ale pamiętajmy, że oni mają tłumik paliwowy, czyli rządowe dopłaty do cen paliw na stacjach. Tylko dlatego jest aż tak tanio.
Zaloguj się aby komentować
Jeśli chcemy regulacji LLMów, to zacznijmy do wymogu:
* oznaczania włączania trybu gorszej jakości
* niższych opłat za tokeny, gdy włącza się tryb gorszej jakości
Pod sankcją bardzo wysokich kar, przy nie oznaczaniu.
https://x.com/realtek12345/status/2043023712245502238
#llm #chatgpt #ai #claude
@fewtoast jest to oczywiste. Subskrypcje nie pokrywają kosztów nawet w 50 proc. Troszke już wcześniej o tym pisałem. Jest powoli presja na realizację zyskow a ich jak nie było tak nie widać. Moim zdaniem pod koniec roku microsoft wykupi resztę chatgpt za przysłowiową złotówkę bo będzie bankructwo i wtedy wszyscy podniosą ceny za subskrypcje drastycznie. Będzie to zmowa a pokiereszowac plany tej zmowy mogą chińskie modele
Może nawet się zdarzyc że tryb ai w przeglądarce bedzie platny

@fewtoast - rozmawialiśmy już tu kiedyś o tym jak modele głupieją z dnia na dzień
Na slashdot.org jest kawałek z New Yorkers jaki to zły klaun z tego Altmana. Myślę, że to wstęp do upadku zaufania inwestorów do firm od AI, a co za tym idzie, ich wpływ na rynek lukratywnych kontraktów na RAM, na politykę HR, będzie słabł.
Cóż, trzymajmy kciuki.
Zaloguj się aby komentować
Ciekawe zjawisko z czarnym Snape: Ludzie znów go nie lubią.
#harrypotter #seriale #warnerbros #hbomax #hbogo #snape #jkrowling

Ale bez spojlerów. Jeszcze nie oglądałem.

@fewtoast Z tą dobrą stroną mocy to ja bym nie przesadzał. Bohatyr to to nie był.
@fewtoast znów? Ja bym raczej powiedział, że oryginalnego Snape'a nie tyle ludzie nie lubili na zasadzie nienawiści, co czuli do niego antypatię. Faktycznie "nie lubić" to ludzie nie lubili Umbridge i tutaj duże propsy dla Imeldy Staunton, która tak doskonale odegrała swoją rolę, że my jako widzowie odczuwaliśmy fizyczną nienawiść do odgrywanej postaci- to potrafi być za⁎⁎⁎⁎ście trudne do osiągnięcia.
Natomiast ten ghetto-Snape to jest kompletnie inny casus. Ludzie nie "nie lubią" jego jako odgrywanej postaci, tak samo jak ludzie tak naprawdę nie "nie lubią" jego jako aktora i z pewnością nie "nie lubią" go dlatego, że on jako aktor jest czarny. Po prostu ludziom się nie podoba, że wcisnęli go w tę rolę mimo, że on tam nie pasuje ze względu na cechy fizyczne, jakie posiada. Najprostsze wytłumaczenie: Snape nie był czarny. Tyle.
I wytłumaczenie tego skąd Paapa Essiedu się tam w ogóle wziął jest dużo prostsze i pragmatyczniejsze, niż sztuczki twórców serialu, czy inny "hate watching". Harry Potter to Warner Bros. Warner został teraz przejęty przez Paramount i mimo, że w umowie mają zapewnioną niezależność, to nie ma co się oszukiwać- WB będzie robić teraz wszystko, żeby nie wtopić przed nowym inwestorem, który wybulił na nich- jakby nie patrzeć- w c⁎⁎j siana. A że sytuacja jest jaka jest i te wszystkie blm-dei-dajwersity-srity-tity ruchy jeszcze do końca nie wyzdychały, to po prostu postanowili chuchać na zimne. Że im się to odbije czkawką i krytyką fanów- z pewnością, ale przynajmniej nie będą mieć na karku wojujących pierdolców, którzy widząc, ze c⁎⁎ja by zdziałali wyjąc do WB od razu by polecieli wyżej robić gnój. A wyżej jest Paramount.
Zaloguj się aby komentować
Wiem co bym chciał: Obowiązkowe (pod groźbą bana) oznaczanie kont i chociaż wiadomostki pisanych przez boty, i w YouTube (czy innej platformie).
Opcja, że np.: ja nie chcę dostawać wiadomości od bota ani mieć w polecanych filmów od bota, że taka blokada na to - nie chce mieć styczności bezpośredniej z botem.
Bo taki bot ci przyjcie, i coś bełkocze w odpowiedzi. I czemu ty masz się z tym użerać w miejscu dla ludzi, czyli w komentarzach?
Nie mam nic przeciwko, jeśli boty będą pisały w wartościowy sposób, ale one takie nie są. Jak widać, generują tylko bełkot.
#ai #llm #bot #chatgpt #youtube

@fewtoast czyli w skrócie chciałbyś weryfikacji ludzi w internecie, czym zabijasz prywatność
Zaloguj się aby komentować
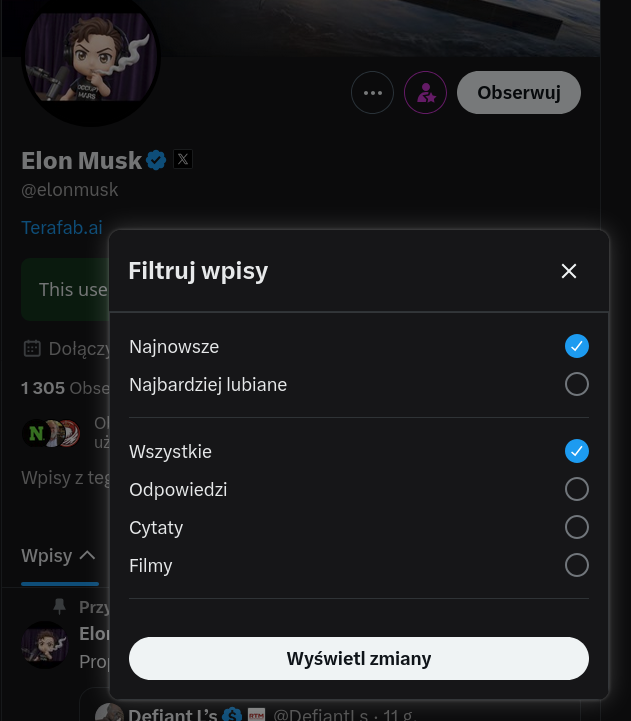
Dodali ekstra filtrowanie wpisów z profilu
Nadal nie dodali filtr "tylko wpisy"
Więc nadal nie mogę zobaczyć samych wpisów danej osoby, bez podanych dalej.
#elonmusk #twitter #userinterface
Zaloguj się aby komentować
Nowa Hermiona wygląda jakby miała pobrudzoną twarz w tej scenie.
#harrypotter #hbogo #hbomax #hermiona #punisher #marvel #daredevil #mcu
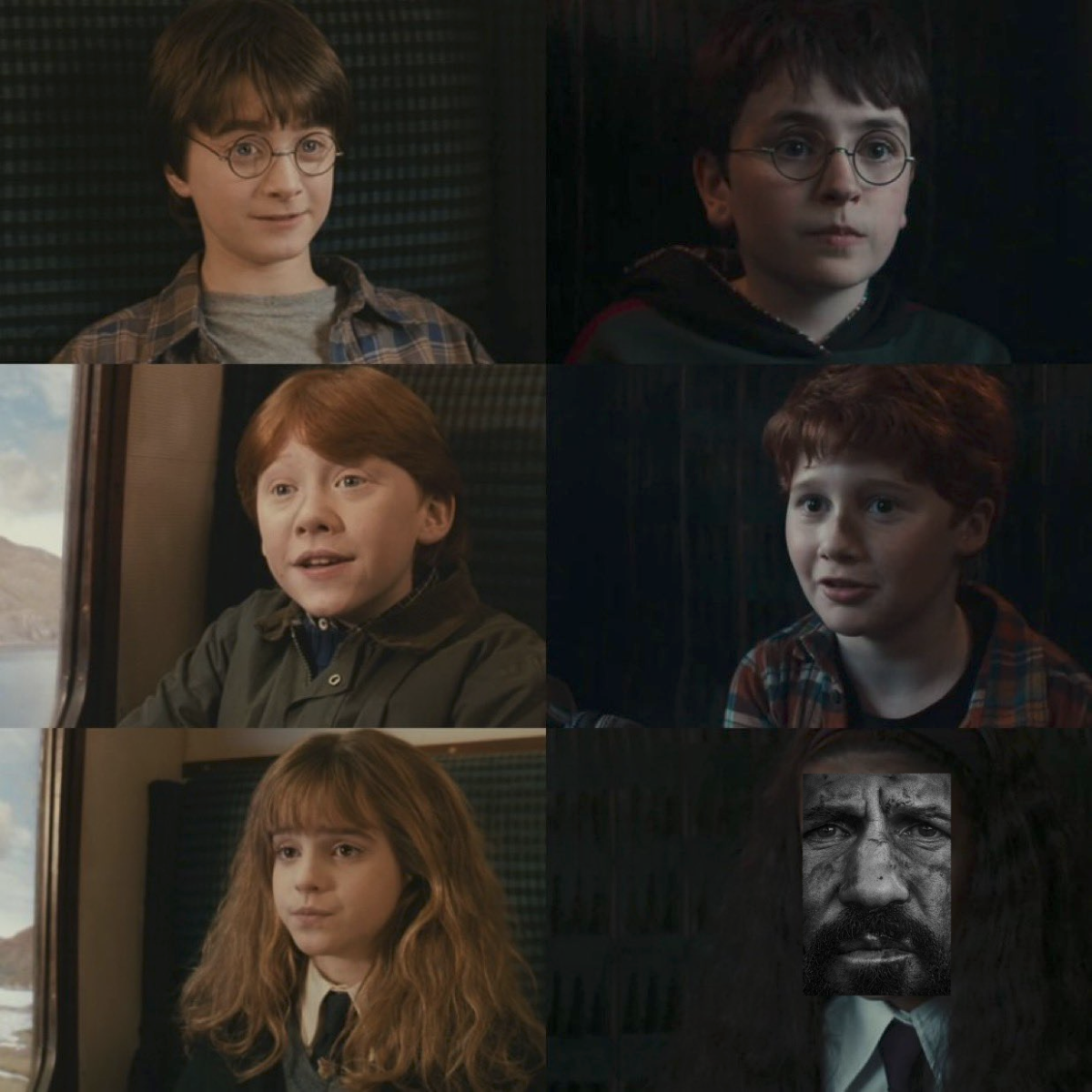

@fewtoast Ktoś ewidentnie horroryzuje filmy. Teraz to wszystko wygląda jak wojna w Wietnamie.
Zaloguj się aby komentować
Czy odwrócono krzywdę Tomasza Komendy? NIE!
Bezpowrotnie odebrano mu potencjalne 1/4 życia z marszu a resztę życia miał w ogromnym cierpieniu psychicznym, był niezdolny do życia w społeczeństwie i nadal w jakiś sposób był napiętnowany.
Tylko że umarł na raka dość szybko po wyjściu z więzienia, więc zabrano mu gdzieś POŁOWĘ ŻYCIA.
Wyrok kary śmierci został wykonany w 3/4 (zabrano mu 18 z 24 pozostałych lat życia, licząc od momentu pójścia do więzienia) - Jakkolwiek to brzmi, to tak właśnie się wydarzyło.
Zadośćuczynienie dostanie jego dziecko i zdążył spłodzić to dziecko - to jedyne co uzyskał. I może trochę odzyskaną sprawiedliwość.
#tomaszkomenda #karasmierci #sadownictwo #prawo #stanowski #klodzko


@fewtoast Po wyjściu z więzienia też jakoś super nie było. Wprawdzie wygrał proces i dostał odszkodowanie, ale potem pojawiły się oskarżenia o przemoc ze strony bardzo szybko znalezionej partnerki. Pytanie czy nie trafiła mu się jakaś golddiggerka
Niestety przykald co się dzieje jak się steruje ręcznie prokuratura
Zaloguj się aby komentować
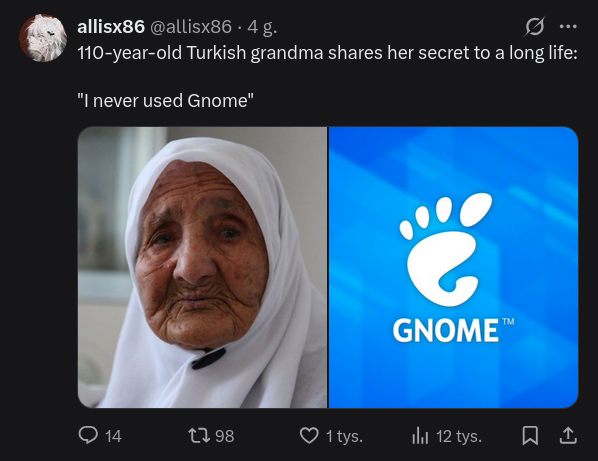
Gdy Twitter zauważy, że interesuje cię temat GNOME:
To jest tak że algorytm bierze najgorsze najgłupsze najmniej wnoszące wpisy z danego tematu, który cię według Twittera interesuje.
I wtedy zalewa cię takim spamem, często wielokrotnie to samo ale z różnych kont.
Aktualnie oficjalnie to Grok reguluje Dla Ciebie na Twitterze.
#grok #llm #ai #twitter #elonmusk
@fewtoast a żeby to tylko to raczysko. Taki niedojebany "algorytm" jest wszędzie- czy to na twixterze, czy na fejsie, czy na innym YT. Wszędzie dostajesz tylko zalew spamu i syfu, który nie potrzebowałeś, bo na pewnym etapie egzystencji wykminili, że po co ci dawać dokładne wyniki (a przecież to już mieliśmy i to z 15 jak nie więcej lat temu!), jak można serwować gówno, a ty się przez to będziesz musiał przeklikiwać. I cyk 2 cele spełnione- raz, że będziesz generował ruch na ich stronach, a dwa- a nuż klikniesz na coś ekstra po drodze.
Zaloguj się aby komentować
Typowa odpowiedź ChatGPT od długiego czasu:
Czy te drzwi są czerwone? Tak – są zielone.
#chatgpt #ai #llm


Jesteś pewien że to nie ty się mylisz?
@Prytozord Kto pyta nie błądzi.
To jakaś dziwna przypadłość. Podobnie wygląda to w Gemini.

? To coś nowego? Z czyms takim jeszcze sie nie spotkalem
@Hjuman Ja mam tego dużo, i coraz więcej ostatnio, aż sam się dziwię.
A jeszcze dłużej było różne sformułowania jak "Dokładnie" "Teraz rozumiem" a potem gada jakby nic nie rozumiał albo dokładnie sprzecznie z tym, co gadał w poprzedniej odpowiedzi. Ja to wprost w meta prompcie blokuję, więc te AI zachowują się jak generatory synonimów, byle jednak wcisnąć tam takie wstępne irytujące słowo.
Zaloguj się aby komentować
Ewa dała sygnał Mentzenowi, w formie ciepłego wywiadu z Braunem i mówiąc, że startuje do polskiego parlamentu,
Mentzen w odpowiedzi zrzucili ja z funkcji prezesa okręgu podwarszawskiego i powiedział, że ma siedzieć w parlamencie unijnym i tam się sprawdza.
Wszyscy widzieli że Ewa jest na wylocie i wreszcie dziś Ewa powiedziała: na razie Sławek, idę do RN i startuję do polskiego parlamentu od nich.
https://x.com/SlawomirMentzen/status/2036783769013699010
#polityka #mentzen #ewazajaczkowska #nowanadzieja #konfederacja

Komentarz usunięty przez moderatora
Ewa Braun, k⁎⁎wa, dosłownie.
jest sie kim przejmowac¯\_( ͡° ͜ʖ ͡°)_/¯
Zaloguj się aby komentować
Tusk kryje pedofili i zoofili. Niech każdy zapamięta.
TVN z ekipą aktywnie zagłuszają jak się powie o skazanych pedofilach w Platformie Obywatelskiej.
#polityka #tusk #platformaobywatelska #tvn
@fewtoast uwielbiam takie "mertoryczne" wpisy ludzi zamknietych w swoich bańkach informacyjnych.
Wołaj sobie maxymiliana będziecie się jak małpy napierdalać patykami.
Jeden będzie krzyczeć "ryży zlodziej" drugi "batyr pseudokibic"
A my będziemy się przyglądać bez słowa.

@Ten_koles_od_bialego_psa A co mnie batyr obchodzi? A temat to gwałty pedofilia i zoofilia, a nie jakieś tam twoje lajtowe "ryży złodziej". TVN ucisza temat, dla Gozdyry temat nie istnieje, PO udaje że nie zna tematu.
@fewtoast taki komentarz jakiego sie spodziewałem.

@fewtoast chodzi Ci o syna Kurskiego, którego pedofilię zacierał cały aparat państwowy PIS?
@100mph Ty serio to robisz? xD
@fewtoast Tak, a wiesz dlaczego? Bo PO ma 30 tys. czlonkow a ludzie, o ktorych piszesz uslyszeli wyroki. Ma sie to nijak do stwierdzenia, ktorego uzyles. Jak to porownac do sytuacji, w ktorej podejrzanego broni nawet prokurator?
@fewtoast Problem polega na tym, że prawicowe media albo coś nie dopowiedzą, albo po prostu kłamią i ciężko nawet zweryfikować ich treść.
Odniosę się do radia Wnet co linkujesz:
https://www.instagram.com/p/DQoN7ypkdKS/
Szukam szukam jakichś większych detali, bo po prostu wiem, że samo bycie neosędzią nie jest podstawą do ponownego rozpatrzenia. Musi być coś jeszcze, stąd mnie zaintrygowało.
I mam to:
https://x.com/DPawelczykW/status/2003427164511686708
Co prowadzi do niezależnej:
https://niezalezna.pl/polska/dziadek-gwalcil-maloletnia-wnuczke-uchylono-wyroki-obu-instancji-powod-neosedziowie/559687
Sąd Najwyższy rozpoznał kasację 18 listopada 2025 roku. Uchylił wyrok Sądu Apelacyjnego w Rzeszowie ze względu na rzekomą wadliwość składu orzekającego, tj. „nienależycie obsadzony sąd”. Sprawę zwrócono do ponownego rozpoznania.
Zdecydowali tak sędziowie Sądu Najwyższego Zbigniew Puszkarski, Kazimierz Klugiewicz oraz Waldemar Płóciennik.
No, spoko, tylko że, orzeczenia SN są publicznie dostępne. Więc wyszukiwarka i mamy to! Jedyny wyrok SN tego dnia w takim składzie!
https://www.sn.pl/sites/orzecznictwo/Orzeczenia3/IV%20KK%20421-25.pdf
Tylko, że....Sędziowie się zgadzają, data wyroku się zgadza, tylko tak coś sprawa nie bardzo....
I jak mam wierzyć jak jest taki burdel? strasznie mnie wkurwia tego typu dziennikarstwo.
@Syster Przecież to 18 grudnia a nie listopada.
Niezależna źle napisała.
@fewtoast i 18 grudnia również nie jest prawdziwą datą. 18 grudnia nie było ani jednego orzeczenia SN IK przerzucającego do ponownego rozpatrzenia. A już na pewno nie w składzie jaki się powtarza czy to na niezależnej czy na Xie.
W ogóle w tym dniu większość wniosków zostało odrzuconych. Swoją drogą nieźle, to chyba jakaś automagiczna droga na którą wszyscy liczą - większość powołuje się na nieprawidłowy skład, prawie nikomu się to nie udaje.
Zaloguj się aby komentować
Dla mnie Ciocia Kasia to jeden do jeden agent Fox z Harold i Kumar. xD
https://x.com/look997_/status/2036500682845335599
#polityka #mentzen #fundacjerodzinne #oswiadczeniemajatkowe #pelczynska #ciociakasia
Jestem za
@sireplama a za "pomyłki" w oświadczeniach majątkowych powyżej jakiegośtam % - utrata mandatu.
@sireplama A bawi cię jej atak personalnie w Mentzena, gdy on od dawna ujawnia majątek swojej fundacji rodzinnej?
https://x.com/SlawomirMentzen/status/2036393769679945932
Zaloguj się aby komentować
Doskonała analiza, rozgrzane masy ludzi są podobnie szkodliwe co farma botów.
https://x.com/gps65/status/2036101230771016135
#twitter #facebook #socialmedia #sociologia #ai
@fewtoast Obecnie jest trend na wprowadzanie weryfikacji wieku, a tuż za rogiem czeka weryfikacja tożsamości przez system operacyjny (o tak!). Bez tego internet nie będzie czysty od AI, ahhh, po wprowadzeniu weryfikacji również nie będzie : )
@Marchew Przeczytaj, to zobaczysz że to nie rozwiąże problemu, bo problem jest taki sam przy masie rozgrzanych prawdziwych autentycznych ludzi. GPS mówi że trzeba eliminować głupie algorytmy, premiujące porywczość ludzi.
Zaloguj się aby komentować
Nie ma tu żadnego negatywnego skojarzenia, cztery razy pojawia się słowo „murzyn” i zawsze jest to skojarzenie pozytywne.
#jezykpolski #murzyn #rasizm #jedzenie #psy

Brakuje Śląskiego murzyna. Takiego z kiełbasą
Zaloguj się aby komentować
Parszywe cenzorskie hieny chcą dopaść Linuksa. A ten się broni w sposób, który boli serce.
https://x.com/Pirat_Nation/status/2034224293807100363
#linux #cenzura #polityka #brazylia #archlinux


No w sensie dlaczego devów tego projektu powinny interesować jakieś losowe prawa wprowadzane w Brazylii xD.
Zaloguj się aby komentować


