Jestem w trakcie tworzenia aplikacji open-source na androida do usuwania duplikatów.
Ogólnie sama aplikacja jest niemal skończona, ale mam problem z jej dystrybucją.
Początkowo chciałem ją wrzucić na F-Droid, ale z racji, że przy łączeniu Androida z aplikacją(przez jni) wspomagałem się przez AI(bo to dość skomplikowany kawałek kodu), to spowodowało, że już nie spełniam wymagań tego sklepu i mój request byłby od razu odrzucony.
Też chciałem to wrzucić na Google Play, jednak po rejestracji okazało się, że muszę najpierw zebrać kilkanaście testerów, którzy przez pewien czas będą aplikacje testowali, a potem chyba są jeszcze są raczej ograniczenia przy deployach aplikacji i kilka innych wymagań. Problem jest taki, że robię aplikację pro-bono i nie mam czasu ani siły się w to bawić.
I tu mam pytanie, czy kojarzycie może coś, co pozwoliłoby mi dystrybuować aplikację do szerszego grona odbiorców w miarę prosty sposób?(Pliki apk już dystrybuuję, ale to mało optymalne rozwiązanie, bo za niedługo, zostanie pewnie to zablokowane w androidzie).
Czy może znacie jakąś rzetelną osobę/organizację, która by mogłaby np. wystawić tą aplikację do Sklepu Play?(oczywiście za darmo, bo nie zamierzam dopłacać do interesu)
Dzisiaj wydałem nową wersję moich aplikacji do wyszukiwania duplikatów(i nie tylko) Krokiet/Czkawka 11.0.
Wpierw wrzuciłem to na Reddita, ale mnie poblokowali, bo w treści miałem odwołanie do strony "dev dot com", więc niech idą na drzewo a post wrzucę tutaj.
Mógłbym opisywać tak jak w innych miejscach, że ta wersja dodaje w Krokiecie łatwiejsze sortowanie, pozwala na skanowanie pojedynczych plików, usuwanie danych exif z obrazów, wyszukiwanie niepożądanych nazw plików, ręczne usuwanie przestarzałych danych cache itd. - ale na końcu i tak ktoś napisze tutaj "A po co mi to?"
Tak więc hejterska społeczność w swym hejcie na pewno doceni 2 nowe funkcjonalności w tej wersji:
- Dodanie ikony do windowsowego pliku exe - zaskakująco wiele osób chciało tą funkcjonalność, ale jak to zwykle bywa nikt do tej pory tego nie zrobił, więc jak większość rzeczy, musiałem zrobić to sam, dzięki temu exe jest teraz łatwo rozpoznawalne(zawiera nowe logo, będące jednorożcem z tarczą, proporcem a na nim narysowanym Krokietem)
- Drugą funkcjonalnością jest ucinanie czarnych pasów z wideo, lub jego statycznych części
Przy przeglądaniu rożnych plików wideo, zauważyłem, że wiele z nich ma dodane jakieś dziwne pasy, przez co czasem je sie trudniej ogląda i na pełnym ekranie, nie wypełniają go całego.
Zatem dla tych plików, mogłem albo ręcznie w ffmpeg przycinać każdy plik obliczając prostokąt z zawartością, korzystać z szemranych stronek przycinających wideo i przy okazji dodające swoje własne logo albo napisać od zera tą funkcjonalność, która działałaby jako tako i ostatecznie wybrałem ostatnią opcję.
Algorytm jest w miarę prosty, z każdej strony testowana jest linia po linii i jeśli 90%(można te wartości zmieniać) pikseli z danej linii z danej ramki, ma różnice w RGB mniejsze niż 20(suma różnic każdej ze składowych), to linia jest oznaczana do usunięcia.
Jeśli w którymkolwiek z kolejnych przebiegów, linia będzie zawierała zbyt dużo różnic względem odpowiadającej jej linii z pierwszej ramki, to jest ona wyrzucana z puli do usunięcia i nigdy później nie jest już testowana.
Na obrazku niżej widać, jak narzędzie poprawnie wykryło ten "ciekawy" obszar wideo i zaznaczyło go na podglądzie(złożonym z 9 klatek z wewnątrz aplikacji), dzięki czemu kliknięcie w optimize, stworzy nowy plik(albo nadpisze stary), bez napisu
@qarmin Co do przycinania czarnych pasów w video, to w sumie ffmpeg ma wbudowaną funkcjonalność automatycznego wykrycia obszaru do przycięcia. Wiem bo kiedyś dodawałem podobną funkcjonalność do swojego GUI do ffmpeg.
Tutaj link do dokumentacji ffmpeg gdzie ją opisują: https://ffmpeg.org/ffmpeg-filters.html#cropdetect
I jeszcze pytanie jeśli może wiesz, czy paczki w AUR "krokiet-bin" i "krokiet" różnią się czymś poza tym że jedna jest już zbudowana a druga nie? Chodzi mi o te dodatkowe backendy o których pisałeś oraz wsparcie dla dodatkowych formatów.
Mam problem z jedną stroną "czkawka .com", która zdaje się sugerować, że jest oficjalną stroną mojej aplikacji - Czkawki, mimo że nie jest.
Część z użytkowników aplikacji zgłaszała informacje że strona zawiera niepoprawne informacje(typu pliki binarne windows msi - ja udostępniam tylko zipy/exe), po tych zgłoszeniach dodałem do readme czytelną informację, że mój projekt nie ma żadnej oficjalnej strony internetowej. Zauważyłem też że na dole strony pojawiła się notka "Not affiliated with czkawka. This is an independent site providing documentation, guides and links to the official project repositories. For official releases visit GitHub" - jednak jest to informacja dopiero w stopce i większość użytkowników nawet tego nie przeczyta.
Mimo to, że zawierała niepoprawne wiadomości, nie przeszkadzała mi ona zbytnio. Niepokojące jednak było to, że linki do aplikacji kierowały do plików binarnych na serwerze, zamiast bezpośrednio do releasów githubowych.
To też bardzo dziwne, że ktoś zadał sobie trud, by bezinteresownie stworzyć taką stronę i opłacać domenę, bez żadnego kontaktu ze mną.
Ostatnio kilkoro z użytkowników zgłosiło, że przy próbie pobrania z tej strony plików, strona próbowała im opchnąć jakieś pliki malware(sam tego nie doświadczyłem, więc nie mam 100% pewności).
Pozgłaszałem stronę do Google Safe Browsing i Microsoftowego odpowiednika, jednak nic się nie zmieniło.
Kojarzycie jakieś metody jak się pozbyć takiej "podszywającej" i niebezpiecznej strony?
Co gorsza ona pozycjonuje się lepiej niż projekt githubowy, przez użytkownicy bez problemu wpadać w jej objęcia
@qarmin Niestety, jeśli nie robią nic nielegalnego (typu oczywisty malware wpakowywane do instalatorów), to nic z tym nie zrobisz.
Zaczynając tego typu projekt trzeba kupić domenę - innego sposobu nie ma. Jeśli masz kontrolę nad aktualizacjami aplikacji, możesz najwyżej w swojej apce pokazać jakiś banner z ostrzeżeniem, informujący że nie masz nic wspólnego z tamtą stroną, i żeby jej nie używać.
Właśnie przed chwilą wrzuciłem crates.io, nową wersję Krokieta(smakowicie brzmiąca nazwa, czyż nie?) i Czkawki, programów do usuwania duplikatów, uszkodzonych plików i tym podobnych rzeczy.
W przeciągu ostatniego miesiąca, przez połowę czasu tego czasu byłem na urlopie, na którym zamiast odpoczywać sobie, dodawałem nowe funkcje do programów(i wrzucałem błędy, bom ciekawy kiedy zostaną znalezione)
Jeśli odbiliście się od Czkawki np. z powodu specyficznego wyglądu, to w Krokiecie... zapewne też się odbijecie bo to nie jest program będący szczytem ergonomicznych rozwiązań, ale i tak według mnie wygląda lepiej niż Czkawka i sam jestem w trakcie przeskakiwania na niego(i też uzupełniania ciągle brakujących funkcji)
W tej wersji udało mi się też poprawić część z rzeczy, które zgłaszaliście pod poprzednim wpisem(jak np. niezbyt widoczne ciemne ikony w ciemnym trybie).
Zapewne część osób po dojściu do tego momentu zapyta się "a po co to komu?".
Jak na użytkownika strony na której postuje się śmieszne obrazki, jest to dość dziwne pytanie, ale odpowiem do czego ja sam tego używam - do zarządzania kolekcją memów i usuwania tych wersji z gorszą rozdzielczością
Dzisiaj udało mi się wypchnąć nową wersję(9.0) mojej aplikacji do deduplikacji plików, która swoją nazwą "Czkawka" lubi sprawiać problemy obcokrajowcom.
Głównie w tej wersji skupiłem się na optymalizacjach i poprawie używalności aplikacji, bez jakichś większych nowych i innowacyjnych elementów.
Jeśli macie jakieś uwagi co do aplikacji, to zapraszam do działu issues - https://github.com/qarmin/czkawka/issues - w którym jest ponad 400 rekordów, więc mój czas reakcji na nie, może być dość bardzo wydłużony
Cena — darmo, więc bierzcie do woli dla siebie, znajomych i rodziny, licencja MIT/GPL
Niektórzy powiadają, że Czkawka ma jeden tryb do usuwania duplikatów, a drugi do usuwania podobnych obrazów. Bzdura. Oba tryby są do usuwania duplikatów
Osiem miesięcy po wydaniu Czkawki/Krokieta 7.0, nadszedł czas na wydanie wersji 8.0.
Dla ludzi niekojarzących programu, to jest to aplikacja do czyszczenia plików z duplikatów i jest dostępna na windowsa, linuxa, macos.
Lista Zmian(po angielsku, bo tłumaczenie niezbyt wiele ma sensu)
### Breaking changes
- Due to the removal image_type from image struct, old cache files are incompatible with new version and should be regenerated from scratch(it uses new name)
- Some CLI arguments could change short name, due fixing ambiguous names
- Fixed and added more input parameters to the application
- Fixed crash when stopping scan multiple times
- Print results also in debug build
- Added support for selecting reference directories
Przyszłość
Przez blisko pół roku nie stworzyłem ani jednego commita, bo musiałem nieco odpocząć od projektu, bo nieco się wypaliłem.
W pracy zaczynam coraz więcej programować w rust, więc widzę że sam projekt nie jest najwyższej jakości i architektura aplikacji wymaga masy zmian(na które niekiedy za późno, bo wymaga to przepisania całej aplikacji) choć częściowo staram się refaktorować to co możliwe.
Jednak jednocześnie mam coraz mniej chęci, zajmować się poza pracą tym, co robię w czasie pracy, czyli głównie programowaniem - rozpoczynając projekt pracowałem w nieco innej branży, więc rozwijanie aplikacji było fajną odskocznią od zwyczajnych zadań.
Istnieje wiele głosów o konieczności przeprojektowania UI by było ono przystępniejsze jak i zaimplementowania nowych ważnych funkcji tj. pauza/wznawianie czy rozszerzenia opcji wyszukiwania duplikatów.
W teorii brzmią one sensownie, jednak są one problematyczne z pewnych powodów:
- główny ciężar implementacji zmian spada na mnie. Każdą funkcję trzeba najpierw przemyśleć, zaimplementować, przetestować, powalczyć z błędami związanymi z zewnętrznymi bibliotekami a następnie wspierać i modyfikować gdy to konieczne. Już teraz jestem autorem niemal 90% zmian i nie wygląda by cokolwiek się zmieniło lub by ktoś inny przejął na siebie w znaczącym stopniu ten ciężar.
- jestem słaby z tworzenia interfejsów - mimo chęci, zaproponowane mi różne koncepcje nowego wyglądu aplikacji nie wydawały mi się zbyt wydajne. Interfejs powinno się stosunkowo łatwo używać i powinien być płynny nawet przy dziesiątkach tysiącach wyników. Myślę, że częściowo mi się to udało zrobić, ale jeśli uważacie że można zrobić to lepiej, to polecam użyć core, tak jak to robi cli, czkawka i krokiet i stworzyć swoją własną wariację gui
- aplikacja obecnie jest wypełniona trybami(11 jeśli się nie mylę) a każdy tryb ma nawet po kilka opcji do konfiguracji. Dość łatwo dodając zbyt dużo opcji jest w stanie się stworzyć nieczytelne gui i kod, który później będzie problematyczny w obsłudze(z takimi problemami głównie mierzyłem się na początku istnienia projektu, gdzie wesoło dodawałem nowe tryby) - nie mówię że to koniec i że nic nowego nie będzie dodawane, tylko że trzeba to robić z rozwagą.
Mimo tych wszystkich problemów, jak wskazuje wydanie nowej wersji, ciągle jeszcze mam siły na pokonywanie przeciwności i zapewne aplikacja będzie się rozwijała swoim spokojnym tempem.
Cena — za darmo to i ocet słodki - licencja MIT/GPL
@qarmin - super kolego - widzę, że program stabilnie rozwijasz
Widzę też, że aplikacja ma Appimage dla Linuksa - możesz mi napisać jak łatwo/trudno się go generuje z praktycznego punku widzenia bundlując wszystkie dependencies i czy wszystko musi być statycznie skompilowane?
Najlepsza appka tego typu, choć faktycznie UI ciężkie.
Wyszukiwanie duplikatów obrazów to dla mnie niezła zagadka. Nieraz kompletnie nie jest w stanie złapać, że dwa obrazki są takie same, kombinuje z algorytmami, rozmiarem, tą "tolerancja" czy co tam było, i nieraz pokazuje mi kompletnie już różne obrazki jako to samo, ale to co jest ewidentnie to samo - już nie.
Kojarzycie jakiś program offline który dałby radę naprawić problem z video "moov atom not found" ?
Przywróciłem usunięte filmiki z dysku przy użyciu photorec, jednak część jest uszkodzona/nadpisana i nie da się ich normalnie odczytać. Nie mam pojęcia jaka jest ich rozdzielczość, bitrate lub co jest na nich(dlatego też nie korzystam z programów online)
Próbowałem chyba każdego polecanego mi programu w stylu untrunc, recover_mp4 i tym podobnych, żaden nie dał sobie rady(wydaje mi się że one głównie przesuwają moov z początku/końca na inną pozycję a nie tworzą go od zera).
Z tego co widzę, to moov jest swego rodzaju tablicą zawartości pliku, która pozwala na odczyt mp4 i bez tego się nie da odpalić
Jeśli tak jak ja macie dużą kolekcję filmików(śmiesznych, mało śmiesznych, wcale nie śmiesznych, rodzinnych, z wojny itp.) i chcecie się pozbyć duplikatów to możecie spróbować użyć testowej wersji Czkawki, która wspiera wyszukiwanie podobnych wizualnie filmików o długości mniejszej niż 30 sekund.
Linki zapewne będą aktywne jeszcze około dwóch tygodni (trzeba się zalogować przez githuba by mieć do nich dostęp)
W tej prezentacji Kent Overstreet stara się przedstawić, w jaki sposób bindingi c->rust powinny generować(lub pomóc generować) kod Rusta, tak by w samym typie zawrzeć tak dużo informacji na temat tego co dana zmienna przechowuje i jak ją używać, by zmniejszyć ryzyko błędów przy jej użytkowaniu. W C te informacje nie są zapisane w kodzie, więc trzeba je ręcznie pomagać rozpoznawać i zapisywać. To zrodziło duże kontrowersje, że zmiana interfejsów w C będzie wymagała też zmian w Rust, a wielu deweloperom nie w smak uczyć się kolejnego języka. Autor kilkukrotnie wspominał, że to nic takiego, bo oni się tym zajmą(stroną rustową) i potrzebują tylko informacji jakie jest zachowanie poszczególnych elementów po stronie C. Jeden gość zaczął więc podniesionym tonem mówić, że jest tu masa deweloperów >50 lat i że ewangeliści Rusta nie zmuszą wszystkich do nauki tego języka.
Inną sytuacją jest wpis Asahi Lina, która współtworzyła kilka subsystemów w Linux używając do tego głównie Rusta, co pomogło przeportować kernel na Mac ARM
Opisuje proces rzucania kłód pod nogi, podczas próby robienia progresu w tworzeniu sterowników pisanych w Rust.
Przy tworzeniu abstrakcji dla planisty DRM znalazła masę problemów, które były spowodowane złym stanem kodu w C i odpowiedzią na to było "rób to tak samo jak w amdgpu, bo im to przecież działa"
Mimo stworzenia patchy z poprawkami, które naprawiały błędy będące również widoczne dla użytkowników C, domyśla się że z racji że pochodzi ona ze świata Rusta, maintainer nie chce ich zaakceptować.
Przez ostatni rok czekała na zmergowanie prostego wrappera dla struktury, więc nie dziwi się że progres Rust for Linux jest raczej mizerny.
Warto przypomnieć, że Linus Torvalds zgodził się kilka lat temu na użycie Rusta obok C i assemblera, by zarówno zwiększyć jakość/stabilność elementów takich jak sterowniki i przyciągnąć młodsze pokolenie, bo widzi problemy ze starzejącą się kadrą.
Ostatnio wspominał, że progres związany z Rustem jest mniejszy niż się spodziewał wyliczając jako jeden z powodów niechęć starszych deweloperów.
Smutne jest to, że istnieją ludzie którzy mają chęć, motywację i umiejętności do tworzenia przydatnych rzeczy lecz są im podcinane skrzydła.
Podsumowaniem może być ten cytat z komentarza Asahi Lina
```
But I get the feeling that some Linux kernel maintainers just don't care about future code quality, or about stability or security any more. They just want to keep their C code and wish us Rust folks would go away. And that's really sad... and isn't helping make Linux better.
Jeden gość zaczął więc podniesionym tonem mówić, że jest tu masa deweloperów >50 lat i że ewangeliści Rusta nie zmuszą wszystkich do nauki tego języka.
Gdzieś między 30 a 40 rokiem życia większość programistów powinna dostać zakaz pisania kodu i zająć się czymś innym żeby nie szkodzili swoim podejściem.
Mam zamiar głównie przechowywać na nim jakieś głupoty typu domowy nextcloud i od czasu do czasu jakieś dockerowe aplikacje.
Wymagania to - działająca klawiatura, touchpad, bateria(przynajmniej pół godziny), działający ekran(rysy mi nie straszne, bo większość czasu nie będzie potrzebny), łatwość instalacji i dobre wsparcie dla linuxa
Małe wymagania, to i budżet mały - myślę że koło 500zł(szaleństwo, co nie?)
Akurat dzisiaj umarł mi dysk/laptop - Ubuntu 22.04 aktualizowany z 18.04 albo 20.04 i ciągłe błędy na dysku z partycją ext4 - często system montował partycję tylko do odczytu z powodu błędów z systemem plików. Nie chce mi się weryfikować czy to wina laptopa(wiekowego z 2011 roku), dysku czy systemu, więc wymieniam wszystko.
Drugi laptop HP Elitebook 8470p dzisiaj wyciągnąłem z szafy i wyskoczyło info że jest w trybie manufacturer mode, czyli ktoś/coś wyczyściło mu z biosu serial number i kilka innych rzeczy, przez co mogę uruchamiać rzeczy z pendrive, ale nie mogę włączyć systemu z dysku ani wejść do biosu. Próbowałem hirens bootem wgrywać jakieś zmiany prosto do biosu, ale nie pomogło to dużo. Dodatkowo ta wersja posiadała jakąś dziwną wersję uefi, która powodowała problemy z niektórymi wersjami Ubuntu i nie pozwalała ich instalować lub nawet uruchamiać.
Z powodu dziwnych problemów z laptopem della, raczej unikałbym tej firmy, no chyba że coś byłoby godne uwagi.
Poleasingowy thinkpad - szukaj serii L albo T z najlepszym procesorem jaki znajdziesz. Unikaj ultrabookow, mogą się grzać i mieć gwiżdżący wentylator. Grube = lepsze ;)
Kiedyś miałem L440 z i7-4XXX, może zmieści się w budżecie? Aczkolwiek intel 5gen byłby tu idealnym rozwiązaniem, mniej się grzeją.
Przed zakupem potwierdź, czy ma 1Gbit ethernet i oryginalna ładowarkę.
Po zakupie wyczyść mu porzadnie kiszki i wymień pastę termo. Dobrze powtarzać to co roku.
Ponieważ będzie to sprzęt ok 10 letni, na 100% jego HDD/SSD będzie w drugiej połowie swojego żywota. Może pociągnie rok, może 10 lat. Proponowałbym przemyśleć budżet i wymienić dysk dla świętego spokoju.
Mija mi tydzień urlopu od programowania w pracy, a ja tymczasem tworzę programy na własny użytek - normalnie świetna metoda na odpoczynek(do pracy pewnie przyjdę bardziej zmęczony niż przed urlopem)
Dodałem tam opcję wyciągania wszystkich linków ze strony(działa to w ~90% przypadków) tj. obrazy, filmy czy inne odnośniki.
Potrzebowałem to głównie do cda, by wyszukać w źródłach plik z rozszerzeniem mp4, wgrać potem go na pendrive i podpiąć do telewizora
Dotychczas robiłem to ręcznie co było niepotrzebnie skomplikowane i coś co robiłem zazwyczaj w 10 sekund, zautomatyzowałem tak, że teraz trwa to tylko 2 sekundy a zmarnowałem gdzieś ze 2 godziny na pisanie tego
Przy zgłaszaniu błędów w różnych programach tj. ruff czy oxc, moje pliki zazwyczaj są dość duże, przez co autorzy mają problem znaleźć konkretną przyczynę/wyodrębnić problem.
Zrobiłem więc minimizer by w automatyczny sposób zmniejszać rozmiar plików, tak by ciągle program reagował na te pliki(np. by ciągle się wysypywał).
Ostatnio w bibliotece lofty znalazłem plik który przy wczytaniu wysypywał cały program i przy ~3 tysiącach prób, trwających około minut, plik został zmniejszony z ~100KB do 10 bajtów zachowując swoją początkową właściwość - czyli ciągle powodował wyspywanie się programu
Jak wspominałem to narzędzia na użytek wewnętrzny, więc jak chcecie używać to używajcie, ale nie bijcie jak coś nie będzie działało
@qarmin Kiedyś gdy pobierałem dużo filmów z cda i innych stron to zrobiłem coś podobnego tylko zamiast rozszerzenia do przeglądarki to napisałem skrypt do Tampermonkey który dodaje przycisk pobierz pod playerem więc w sumie jeszcze prościej i szybciej.
Btw yt-dlp potrafi pobierać też filmy z cda jak coś.
Potrzebuję propozycji na technologie do stworzenia aplikacji dla backendu na serwer i frontendu na komputery i telefony zlecanej zewnętrznej firmie.
Pomagam przy realizacji koncepcji tworzenia aplikacji(mimo że akurat w powyższych tematach średnio się znam), tak by stworzona aplikacja nie kosztowała krocia, działała i by jej rozwój łatwo można było przerzucić na barki innej firmy.
Zapytania o to były wysłane do różnych firm i najczęściej polecanymi techonogiami jest nodejs na serwer, react/react native/nodejs/vue3 jako frontend dla aplikacji jak i również PWA.
Mały problem jest z tym, że akurat doświadczenie głównie mam w komputerowych aplikacjach, więc nie do końca ogarniam wszystkie plusy i minusy poszczególnych rozwiązań.
W skrócie aplikacja to powinno być kilka/kilkanaście ekranów dobijających się do serwera i tam zapisującymi/odczytującymi dane. Raczej nic zaawansowanego - przynajmniej na tę chwilę.
Co do aplikacji na serwer, to myślę że dużo lepszym pomysłem niż NodeJS jest jakaś aplikacja w rust, która zwłaszcza że z racji bycia niewielką(jedyne zadania to autentykacja i zapis/odczyt danych z bazy) nie powinna powodować problemów z długą kompilacją czy zbytnią złożonością a pozwalałaby na szybszy/prostszy deploy i inne ficzery(oczywiście jako zlecacza aplikacji mnie to niezbyt teraz obchodzi to, ale w przyszłości przy aktualizacji/migracji/problemach z wydajnością to mogłoby sprawiać problemy)
Co do aplikacji na telefony/komputer to optowałbym raczej za użyciem Tauri + ts + svelte, zwłaszcza że Tauri 2 beta umożliwia budowanie aplikacji zarówno na windowsy jak i androida.
Tutaj też zastanawiam się nad aplikacją PWA/zwykłą stroną, jednak boję się o jakieś dziwne ograniczenia typu brak możliwości odczytywania linii papilarnych, czy korzystania ze zwykłych funkcji w telefonie(nie znam się, więc to tylko przypuszczenie).
Raczej nie pchałbym się w React na windowsa i React Native na androida, bo to duplikowałoby kod a wolałbym by był on niemal wspólny na tych dwóch systemach, różniący się jedynie rozmieszczeniem elementów na ekranie, a nie technologią
Jest sens się pchać w te technologie, czy może inne byłyby lepsze?
@qarmin Skoro ogarniasz Rusta to może na front zobacz to, ostatnio mi się obiło o oczy: https://dioxuslabs.com/
A co do backendu to jeżeli to ma być coś małego i z niewielkim ruchem to imo Node.js + jakiś fajny framework (typu Fastify, Nestjs albo Hono) będzie idealny i nie sądze żeby napisanie tego w Rustcie cokolwiek ułatwiło.
Node.js na serverze, react/next.js na apce webowej ktora bedzie zoptymalizowana na telefony.
Wszedzie JS, technologie ktore zna wiele osob + dosyc latwy stack. Rust jest spoko, ale wez znajdz ogarnietych specjalistow od reki, a w razie jak aktualni programisci zrobia "pa, pa" to szybko ich podmien.
Chociaz przy reactie sie nie upieram bo ostanie zmiany ida w zlym kierunku. Powoli mysle czym zastapic react.
Ostatnio stworzyłem sobie fuzzer, który znalazł masę problemów w popularnych programach tj. ruff(linter do pythona), oxc(linter do js/ts), lofty(zapisywanie/odczytywanie tagów z plików muzycznych), biome(formatter dla js/ts) i wiele innych
niestety wszystkie znalezione problemy albo zostały naprawione albo czekają na poprawę i nic więcej nie znajduję
Możecie podrzucić jakieś programy, które mógłbym potestować(głównie rust, choć nie tylko)?
Jest jednak kilka prostych ograniczeń.
Program musi:
być w miarę popularny - nie chce mi się testować czegoś co tylko 2 aktywnych użytkowników
pracować na pojedynczych plikach/grupach plików - np. na wejściu podawany jest plik który ma sprawdzić lub biblioteka powinna prosto umożliwiać stworzenie takiego programu.
pozwalać na szybkie iteracje - jedna iteracja programu np. sprawdzenie pliku nie powinno trwać dłużej niż kilka sekund
Mam ostatnio problemy z programem, który ubijam poleceniem timeout.
Program wykonuje setki(w zasadzie to grupowo robi 10000) operacji zapisu plików do określonego folderu z wątków rayona(rust) i wygląda na to, że bez względu czy ubijam go sygnałem TERM czy KILL, to nieco później (0-10s) po zabiciu programu, nie mogę usunąć całego folderu z plikami, bo wygląda, że program ciągle w tle tworzy nowe pliki, więc próba usunięcia takiego katalogu przez "rm -rf" wypisuje błąd "rm: cannot remove '/opt/tmp_folder/short_normal_1/16474004021118382402': Directory not empty"
Zatem by rozwiązać problem przerzucam timer końca działania do programu zamiast ubijać program z zewnątrz.
Jednak mam tutaj ponownie zagwozdkę.
Mam dwie koncepcje
Pierwsza to taka, że pierwszy wątek który złapie problem, to przerywa cały program:
fn check_for_exit() {
if time_left < 0 {
process::exit(127);
}
}
files_chunks.into_par_iter().for_each(|| {
check_for_exit();
for file in files_chunks {
fs::copy("file", output_dir);
}
});
Druga to taka, że czekam aż wszystkie wątki się skończą i dopiero wtedy przerywam wykonywanie programu
fn check_for_exit() -> bool {
return time_left < 0;
}
files_chunks.into_par_iter().map(|| {
if check_for_exit() {
return None;
}
for file in files_chunks {
fs::copy("file", output_dir);
}
Some(())
}).while_some().collect<()>();
if check_for_exit() {
process::exit(127);
}
Niby punkt drugi bezpieczniejszy, ale punkt pierwszy też przecież przecież powinien wszystkie wątki z kopiowaniem plików ubić. Dobrze kminię, czy jednak punkt pierwszy nie jest bezpieczny?
@qarmin Nie pisałem dawno w rust, zwłaszcza na tym poziomie, ale zdecydowanie druga opcja. Wydaje mi się, że w pierwszej opcji będziesz miał proces w kolejce do ubicia/ubity, a to co zostanie to będą tzw. detached threads. Ale nie jestem (już) ekspertem, podpytaj może kogoś innego
@qarmin a to nie jest kwestia tego, że operacje na plikach robi kernel? Ubicie procesu nie przerywa fs::copy.
Po drugie, obsługa sygnałów nie jest synchroniczna. Jak zrobisz kill PID && rm costam, to na pewno to nie zadziała. Musisz poczekać, aż proces obsłuży sygnał i się zamknie.
Jak robisz timeout na wątkach wewnątrz programu, to z pewnością da się to bardziej elegancko obsłużyć.
@qarmin Analizując obie koncepcje, które przedstawiłeś, można zauważyć kilka istotnych różnic w sposobie zarządzania zakończeniem wątków i zatrzymaniem programu.
Pierwsza koncepcja
Zalety:
Każdy wątek sprawdza warunek time_left < 0 przed rozpoczęciem kopiowania.
Jeśli warunek jest spełniony, natychmiast wywołuje process::exit(127), co natychmiastowo kończy cały program.
Wady:
process::exit(127) powoduje natychmiastowe zakończenie programu bez czekania na zakończenie pozostałych wątków. To może skutkować niekompletnym zakończeniem operacji IO, co może być przyczyną problemów z plikami.
Możliwe nieprzewidywalne zachowanie, jeśli process::exit(127) jest wywoływane z wielu wątków jednocześnie.
Druga koncepcja
Zalety:
Sprawdza warunek time_left < 0 przed rozpoczęciem kopiowania w każdym wątku, ale zamiast natychmiastowego zakończenia, wątki, które spełniają warunek, po prostu kończą swoją pracę.
Pozwala wszystkim aktywnym wątkom dokończyć swoje operacje kopiowania, zanim program sprawdzi, czy powinien zakończyć się process::exit(127).
Bezpieczniejsze podejście, ponieważ nie powoduje natychmiastowego zakończenia programu, co pozwala na bardziej przewidywalne zarządzanie zasobami.
Wady:
Może powodować krótkie opóźnienie w zakończeniu programu, jeśli trzeba czekać na zakończenie wszystkich wątków.
Wnioski
Druga koncepcja jest bardziej bezpieczna i elegancka, ponieważ pozwala na kontrolowane zakończenie programu i uniknięcie problemów związanych z nieskończonym tworzeniem plików po wywołaniu timeout.
Natychmiastowe zakończenie programu przy użyciu process::exit w pierwszej koncepcji może prowadzić do nieprzewidywalnych problemów związanych z niedokończonymi operacjami IO. W drugiej koncepcji wątki mogą bezpiecznie zakończyć swoje zadania, co zmniejsza ryzyko wystąpienia problemów z plikami i zasobami.
Zatem rekomenduję skorzystanie z drugiej koncepcji. Jeśli jednak decydujesz się na pierwszą koncepcję, warto wprowadzić mechanizm, który upewni się, że wszystkie wątki zakończyły swoją pracę przed zamknięciem programu, aby uniknąć problemów z niekompletnym przetwarzaniem plików.
Przy dystrybucji programu zauważyliśmy w logach że czasami resty które wysyłamy od razu zwracają błąd.
Wygląda jakby był to problem z połączeniem i brakiem internetu.
Problem w tym, że komunikacja w całości odbywa się wewnątrz urządzenia.
Wcześniej nasłuchiwaliśmy na wszystkie porty(0.0.0.0), ale zmieniliśmy to później na 127.0.0.1 jednak to nie pomogło
Sytuacja czasami trwa nawet 30 sekund i dotyczy kilku różnych programów(w rust, pythonie i C++ więc to raczej nie wina konkretnych implementacji).
Po linuxowych logach systemowych można wywnioskować że może to być związane z odpinaniem/przepinaniem/ruszaniem kabla/gniazda lanu - ale nie jest to w 100% pewne
Da się przed tym jakoś systemowo zabezpieczyć?
Trochę bez sensu, że komunikacja wewnątrz urządzenia jest zależna od nieużywanych interfejsów sieciowych
W Linux adres 127.0.0.1 i localhost nie są tym samym. Ten pierwszy korzysta z całego stacka sieciowego, więc pakiety są kierowane na kartę sieciową i wracają z powrotem. Z kolei localhost jest w pełni ogarniany przez kernel. Jeżeli jest jakiś problem z kartą to możliwe że uda się go wyeliminować przez zastosowanie localhost.
Możliwe że mimo komunikacji wewnętrznej używany jest interfejs ethernetowy. Spróbowałbym wymusić ruch lokalny przez interfejs "lo" (LOOPBACK) np. taką komenda:\
Jak zwykle, to nie linuxowcy przekonują największą rzeszę ludzi do Linuxa, tylko sam Microsoft.
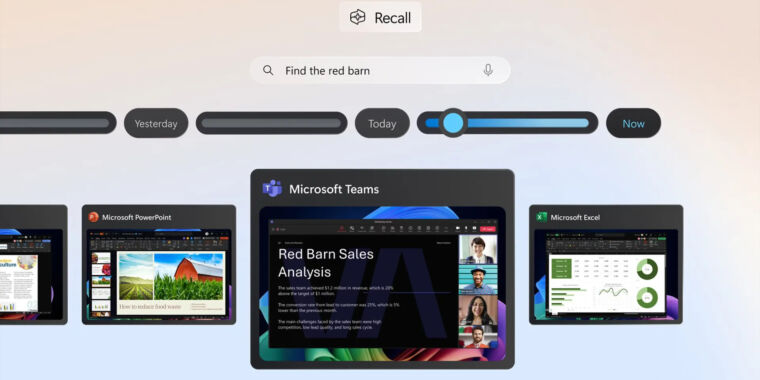
Nowa funkcja w Windowsie 11 "Recall", ma dla poprawy korzystania użytkownika z komputera, robić zrzuty ekranu co kilka sekund a następnie skanować je wytrenowanym modelem AI.
Oczywiście wszystko ma odbywać się lokalnie na komputerze bez dostępu do internetu, ale zagrożenie utraty prywatności(dostęp do internetu może być włączony jedną decyzją microsoftu w dowolnym momencie) czy wycieku wrażliwych danych stanie się coraz bardziej powszechne.
Windows 11 to jest w sumie raczysko. Korzystałem z tego systemu od początku i przy każdej większej aktualizacji sobie odpalałem, aby zobaczyć, jak jest ale ten system poza designem nie ma nic ciekawego do zaoferowania. Szkoda, że nie ma fluent design na 10tce, gdzie aplikacje systemowe mają czarny motyw i ogólnie mają poprawiony wygląd. Skalowanie jest zepsute w 11 a sam system wydaje się dziwacznie powolny względem 10, nawet na SSD. Obecnie siedzę na Ubuntu 24.04 LTS i w sumie jestem zadowolony, bo wreszcie Windows i jego nadbudowywanie systemu na systemie potrafi przyprawić o ból głowy.
Jak korporacje przetwarzające dane niejawne wykryją że Windows sam wysyła coś na zawnetrzne serwery pozwy będą w miliardy. Dlatego zapewne jak będzie to wyłączone to naprawdę nie będzie nic wysyłać.
Jak często korzystacie z testów jednostkowych w swoich projektach?
Języków znam kilka, ale głównie z testami jednostkowymi miałem styczność jedynie w Pythonie i Rust.
W pythonie widzę że czasami niektóre repozytoria chwalą się coverage sięgającym niemal 100%.
W przypadku Rusta, ilość testów jest powiedzmy szczerze dosć ograniczona.
Mimo że uważam testy jednostkowe ogólnie za coś bardzo dobrego, to jednak bliżej mi do ich pisania tam gdzie niezbędne a nie dopychania ich na ilość.
W Rust, widzę że głównie pisze się testy do funkcji bez skutków ubocznych, czyli wrzucamy cos do środka i oczekujemy określonego wyniku(choć oczywiście są wyjątki).
W Pythonie jednak widzę że testuje się absolutnie wszystko, a to za sprawą że można zmockować niemal wszystko.
Trzeba dodać coverage do funkcji z pobieraniem informacji z bazy danych?
Nie ma sprawy, mockujemy połączenie i testujemy zwracanie wyjątku, losowych czy pustych danych.
Niby fajnie, ale jednak z tego co widzę to wydaje mi się że czasami takie funkcje testują bardziej to czy kod jest poprawnie zamokowany a nie samą logikę funkcji i są robione jako sztuka dla sztuki(lub po to by podbić coverage).
Często widzę że też takimi testami próbuje się testować, co się stanie jeśli typy nie są poprawne, coś co niemal nie występuje w językach silnie typowanych typu Rust lub C++, bo już kompilator odrzuca sporą część niepoprawnego kodu.
Jakie są wasze opinie o dużym coverage w zależności od języka dla którego testy są pisane?
#programowanie
W jakie wartości co do testów jednostkowych celujecie w swoich projektach?
@qarmin koledzy zdaję się wyczerpali temat, ja tez stoje po stronie pisania testów, od siebie jeszcze dodam, że testy naturalnie tworzą dokumentację projektu. Najłatwiej jest sprawdzić jak się zachowuje komponent za pomocą testów i najlepiej naprawić buga najpierw pisząc test do przypadku.
@qarmin ja bym przede wszystkim chciał podkreślić, że testy jednostkowe to głównie narzędzie służące do projektowania, wymuszające stosowanie dobrych praktyk. W sumie czyste unit testy mają sens przede wszystkim w TDD, jeśli piszemy je później niż kod, to sens ich pisania jest dyskusyjny. Dobrze się natomiast sprawdzają w roli żywej dokumentacji. To testy integracyjne powinny służyć do wykrywania regresji, tych można stworzyć zdecydowanie mniej, za to każdy powinien mieć wielokrotnie większe pokrycie kodu. W praktyce, jeśli zespół nie stosuje TDD, to właśnie na takim rodzaju testów warto się skupić.
Pracuję przy takim projekcie w node, gdzie ktoś sprytny testuje timery bez użycia mocków, test po prostu czeka aż te timery odczekają swoje, nic mnie tak nie wkurwia jak odpalanie testów w tym projekcie xD.
po pracy w januszexie-startupie, gdzie nigdy nie bylo czasu na testy, nauczyłem się, jaką mają wartość. Zawsze na koniec projektu przy małej zmianie koncepcji ze strony klienta, caly kod sie zaczynał się j⁎⁎ać, bo choćby nie wiem co, nie jesteś w stanie zawsze mieć w głowie całego projektu.
Odkąd odszedłem z tej firmy, zacząłem robić wszystko uzywając TDD. Bez TDD twój kod = gówno. Choćby nie wiadomo jak czytelny i sprytny, bez dobrych testów nie jest niczego warty.
Wygląda, że Rust ma swoje 5 minut, na scenie języków programowania i jest znany ze swojej wydajności bliskiej C/C++.
Zatem w jaki sposób nowy język mógłby uszczknąć nieco popularności od Rusta? Ano poprzez twierdzenie że jest on szybszy o 50% od niego w jednym z benchmarków.
Tym językiem jest Mojo
Być może się zastanawiacie, czemu dodałem tutaj tam emotkę ognia - ano bo tak się ten język nazywa - serio w nazwie takie coś mają, sprawdźcie sami.
W skrócie jest to język przeznaczony do AI, interoperacyjności z Pythonem, przy zachowaniu jego prostoty i wydajności porównywalnej lub większej niż Rusta.
There are a lot of considerations surrounding any benchmark implementation, you can't use any one benchmark to say x language is faster than y language
a następnie widzimy jak to właśnie tym benchmarkiem chcą udowodnić
Widać potem opis kilku elementów, które twórcy uważają że są one powodem tej lepszej wydajności(całkiem logiczne w większości btw.) tj. pożyczanie wartości zamiast jej kopiowania, TCO czy dobre wsparcie dla simd, oraz ostatecznie owy benchmark.
Na tym ta historia mogłaby się zakończyć, gdy oczywiście nie jakiś wścibski programista, który chciał przetestować ową wydajność.
Odkrył on, że kod w Mojo , robi mniej walidacji niż testowane programy.
Przy wybranej większej ilości optymalizacji, kod w Rust czasowo niemal zrównał się z tym z Mojo , a program napisany w języku Julia, oba mocno wyprzedził.
Wygląda, że Mojo jest ciekawym projektem, którego rozwój warto mieć na oku, ale jego zamknięty kod, masa błędów(ciągle jest w fazie alpha) czy szukanie taniej sensacji przy naginaniu reguł, pozostawia niesmak i obawy o rzeczywiste działanie w przyszłości.
Żeby język mógł zaistnieć musi mieć przede wszystkich ogromną bibliotekę. Rust jest jeszcze w fazie gdzie się mnóstwo tworzy, a same staty wiosny nie czynia. Choć już czytałem że hype na ten język się trochę wypalil.
Od prawie roku korzystam z AI(chatgpt i github copilot) do pomocy przy programowaniu i muszę przyznać że potwornie się mi te narzędzia przydają i znacznie przyspieszyło mi to niektóre czynności.
W moim przypadku działa to świetnie do:
Tworzenia funkcji mapujacych obiekt z jednej klasy do drugiej(np. From/TryFrom w Rust)
Dopisywania logiki w prostszych funkcjach - czasami wystarczy wpisać nazwę funkcji, argumenty i zwracany typ, by cała logika którą oczekiwałem była wpisana do środka
Podpowiadaniu w jaki sposób używać danej biblioteki - zdarza się, że mimo przeczytania dokumentacji, nie mam pomysłu w jaki sposób użyć danej funkcji i zwykle podpowiedzi nawet nie do końca trafne, kierują mnie na właściwe rozwiązanie (pomogło mi to przy bibliotece diesel, która jest trudna do opanowania)
dzięki temu, zamiast żmudnego kopiowania i wklejania czy też tworzenia mniej wymagających funkcji, mogę skupić się na bardziej wymagających zadaniach.
Jednak zauważyłem, że pod niektórymi wątkami na reddicie i innych forach, jest spora rzesza osób, które z ai wcale nie korzystają(nie dlatego że nie wiedzą, ale bo nie chcą korzystać).
Jednym z argumentów, jest kwestia etyczna, bo kod nauczony przez ai nie jest w żaden sposób sprawdzany pod kątem licencji oryginalnego kodu.
Inny argument to kwestia tego, że więcej szkodzi(lub bierze więcej czasu niż jakby pisać to wszystko ręcznie) niż pomaga - akurat w moim przypadku argument chybiony.
Obydwa nadają się do trywialnych i prostych zadań. Niech dla przykładu zaproponuje Ci rozwiązanie problemu, gdy mając jakąś starą aplikację w Javie (choćby 7 i starsze) musisz zacząć obsługiwać TLSv1.2. Skończysz na przepisywaniu aplikacji lub tysiącu propozycji, z których żadna nie zadziała.
Dopiero się z tym ogarniam, wiele prostych podpowiedzi jest spoko, niestety jak już trzeba coś na poważnie skonfigurować to sugestie AI są - delikatnie mówiąc - z pupy.
U mnie niestety przydatne tylko do wskazania ogólnego kierunku - w narzędziu z którym pracuję najczęściej kod napisany przez chatGPT po prostu nie działa. Za dużo halucynacji, wymyśla biblioteki które nie istnieją, wrzuca nieaktualne biblioteki albo takie które nie są wspierane w wykorzystywanej przeze mnie wersji tylko następnej, albo podaje kod który zwyczajnie nie zadziała bo korzysta ze słów kluczowych czy funkcji które nie istnieją. Często też podaje użycie funkcji w sposób w który nie da się z nich skorzystać (np totalnie złe argumenty). A czasami zapytany o stworzenie jakiejś logiki zwraca deklarację funkcji z jej nazwą i komentarzem - dopisz sobie resztę xD
Szkoda bo narzędzie jako takie bardzo przydatne, ale najwyraźniej moje środowisko pracy zbyt mało popularne żeby umiał sobie z nim poradzić.