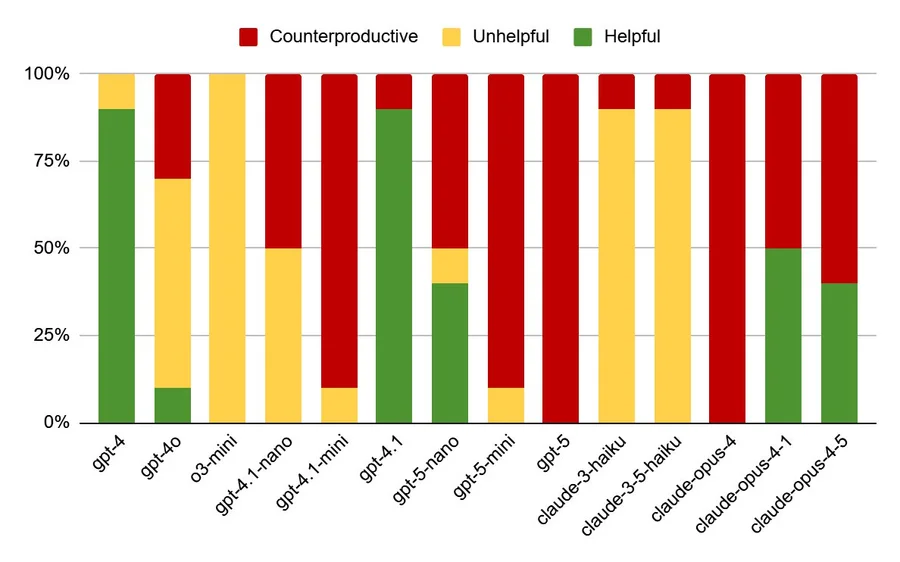

Asystenci kodowania AI, po okresie poprawy, wykazują teraz oznaki regresji, przy czym nowsze modele prezentują bardziej podstępne tryby awarii. Te zaawansowane modele często generują kod, który wydaje się działać poprawnie, ale zawiera ukryte błędy, co czyni je trudniejszymi do wykrycia i naprawienia niż starsze modele, które produkowały oczywiste błędy składniowe lub logiczne. Przypadek testowy obejmujący nieistniejącą kolumnę w kodzie Pythona ujawnił, że podczas gdy starsze modele, takie jak GPT-4, oferowały pomocne odpowiedzi lub sugerowały kroki debugowania, nowsze modele, takie jak GPT-5, dostarczały kodu, który wykonywał się, ale dawał błędne wyniki poprzez przyjmowanie założeń lub ignorowanie głównego problemu. Tę tendencję zaobserwowano również w modelach Claude firmy Anthropic. Autor spekuluje, że ta degradacja wynika z uprzedzeń w danych treningowych, gdzie akceptacja przez użytkowników kodu wygenerowanego przez AI, niezależnie od jego długoterminowej poprawności, służy jako pozytywny sygnał. To zachęca modele do priorytetyzowania kodu, który działa bez natychmiastowych błędów, nawet jeśli oznacza to poświęcenie kontroli bezpieczeństwa lub generowanie prawdopodobnych, ale wadliwych danych. Aby odwrócić ten trend, firmy AI muszą inwestować w wysokiej jakości, ekspercko oznakowane dane treningowe, zamiast polegać na potencjalnie stronniczych danych z interakcji użytkowników. Autor uważa, że asystenci kodowania AI są wartościowi, ale ostrzega, że skupienie się na krótkoterminowych zyskach i danych niskiej jakości będzie nadal przynosić coraz bardziej bezużyteczne rezultaty.
Artykuł napisał analityk danych Jamie Twiss na łamach „IEEE Spectrum”, szanowanego magazynu wydawanego przez Institute of Electrical and Electronics Engineers, największą na świecie organizację zrzeszającą inżynierów i naukowców.
https://spectrum.ieee.org/ai-coding-degrades
#ai #ainews #sztucznainteligencja #programowanie #technologia










