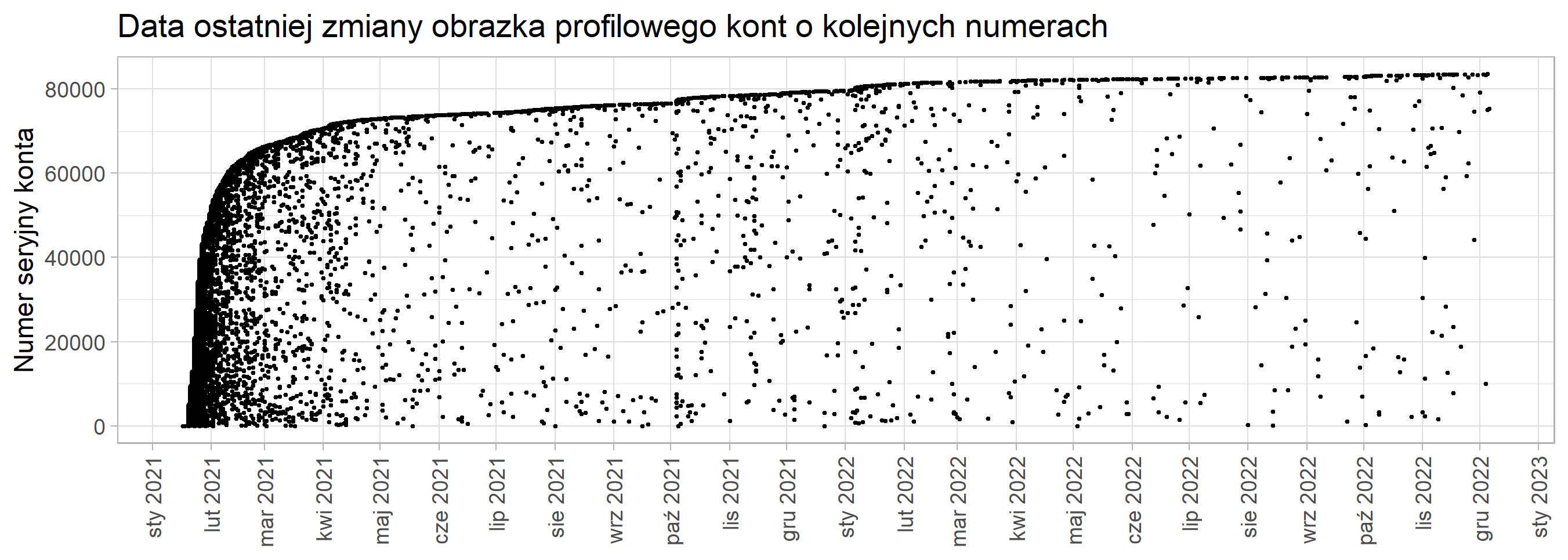
Zapraszamy wszystkich do przeczytania nowego posta https://www.hejto.pl/wpis/czesc-wam-troche-czasu-minelo-od-naszego-ostatniego-posta-ale-juz-po-naszym-sezo
Prowadzimy firmę zajmującą się pisaniem scraperów i pobieraniem danych z internetu.
I jak na tym niby zarabiacie ? W sensie ok,rozumiem, pozyskujecie jakieś dane,może nawet są one sensownie sformatowane ale kto to potem głównie kupuje ? Oczywiście nie żebym chciał od was info o konkretnych klientach czy coś,TO JEST OCZYWIŚCIE WASZA TAJEMNICA PRZEDSIĘBIORSTWA itd,ale na jakiego typu dane najczęściej macie klientów to może napisać możecie ?
z mojego wstępnego OSINTu na waszej stronce wychodzi,że to jakieś statystyki pod marketing - mam rację?
W sensie - surowiec do #datamining to jest,ale tylko surowiec,więc dziwi mnie trochę,że tak wąska specjalizacja i jakoś to jedzie. No chyba,że startupem jesteście,wtedy mniej dziwi.
@dsol17 Raczej nie jedzie, ale jakaś próba swojego biznesu jest
Ze swojego doświadczenia takie scrapery są bardzo słabo opłacalne jeżeli nie robisz tego na bardzo szeroką i profesjonalną skalę a liczysz na to, że uda ci się trafić w trend użyteczności (np. zescrapowanie nr ksiąg wieczystych dla każdej działki w momencie, gdy to było możliwe na geoportalu itp).
Napisałem kilka scraperów bardziej pod siebie typu OLX, otomoto, allegro czy inne, zazwyczaj opłacalność tego kończy się już zanim stworzysz projekt, więc raczej jest to dla własnej satysfakcji
Ooo kocham takie kodowanie, pisałem kilka wtyczek do aplikacji jakie mamy u mnie w firmie i to jak słabo zaprogramowane są aplikacje topowych firm to nóż się w kieszeni otwiera. Przeszedłem piekło z elementami iframe więc już za dużo mnie nie zaskoczy
Dzisiaj zajmiemy się analizą i rozgryzaniem kodu Steam'a.
Brzmi fajnie, lecz post jest dosyć ciężki i skomplikowany.
Z drugiej jednak strony pokazujemy jak wygląda praca z namierzaniem danych i próbami ekstrakcji ich. Oczywiście można uprościć ten kod korzystając z np. Selenium, ale jak poprzednio pisaliśmy sęk w tym, aby scraper był szybki i zużywał jak najmniej zasobów. Dlatego zostajemy przy HttpClient mimo, że wymaga to więcej pracy od nas.
@szoz świetnie to określiłes "w detektywa", dokładnie tak jest! najlepsza zabawa jest właśnie z zabezpieczeniami antybotowymi "pokonanie" jakiegoś rozwiązania, z którego duże sajty korzystają daje rzeczywiście satysfakcję!
wspomniany już LinkedIn koncertowo przewalił sprawę w sądzie. Scrapowanie publicznie dostępnych danych (w tym profili na Albicli) jest w pełni legalne i nie różni się niczym od ręcznego odwiedzania profili. Zupełnie inną sprawą byłoby gdyby scraping spowodował niedostępność usługi i to już mogłoby być potraktowane jako atak DoS i tutaj Albicla miałaby w sądzie pole do popisu.
Zapraszamy wszystkich do zapoznania się z nowym postem! https://www.hejto.pl/wpis/czesc-wszystkim-to-znowu-my-wink-prowadzimy-firme-zajmujaca-sie-pisaniem-scraper
Ktoś miał podobny problem z pycharm? Najpierw wywaliło mi w piątek selenium i nie odpalił mi się, żaden test. A dzisiaj to #programowanie #python #selenium