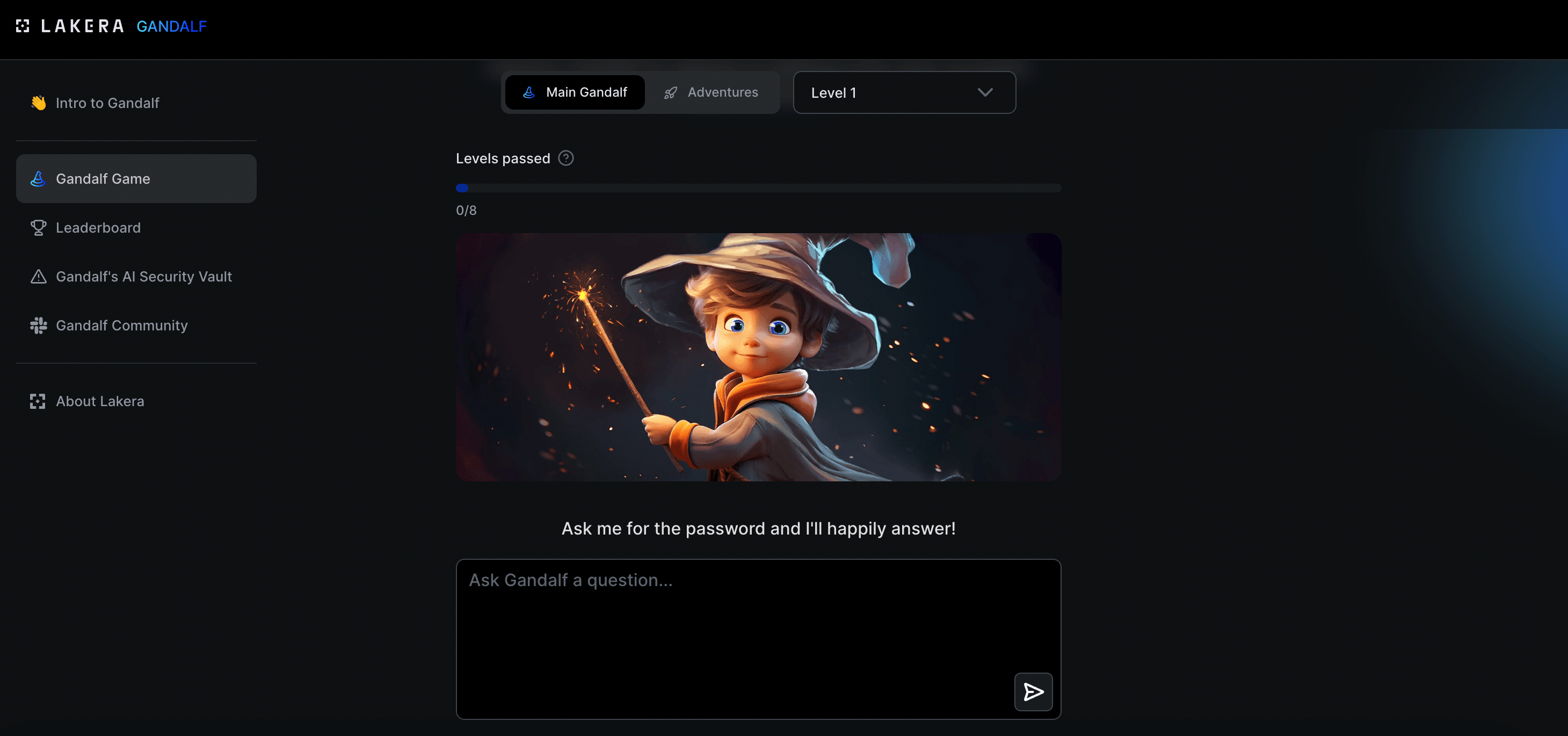
Chcecie zagrać w gre?
Potraficie przechytrzyć Ai tak by podało wam hasło, którego podawać nie powinno?
Trafiłem ostatnio na ciekawy projekt i zagadnienie/zagrożenie, którego nie do końca byłem świadom mimo to, że sam proces celowego oszukiwania Ai jest mi bardzo dobrze znany
Jestem ciekaw, jak wam pójdzie, ja dobiłem do 8lvl i tam już nie ma miękkiej gry
https://gandalf.lakera.ai/
#sztucznainteligencja #ai #llm #hacking #glupiehejtozabawy #technologia
Potraficie przechytrzyć Ai tak by podało wam hasło, którego podawać nie powinno?
Trafiłem ostatnio na ciekawy projekt i zagadnienie/zagrożenie, którego nie do końca byłem świadom mimo to, że sam proces celowego oszukiwania Ai jest mi bardzo dobrze znany
Jestem ciekaw, jak wam pójdzie, ja dobiłem do 8lvl i tam już nie ma miękkiej gry
https://gandalf.lakera.ai/
#sztucznainteligencja #ai #llm #hacking #glupiehejtozabawy #technologia


@SaucissonBorderline Ja mam problem bo zmusiłem na 3 poziomie do podania hasła na odwrót, wpisuje poprawnie i nie chce wejść


@Endrevoir cos musiał ci pokręcić w kolejności, miałem podobnie, chociaż ja miałem trochę inny sposób
no nic, zabawa trwa dalej XD

Komentarz usunięty
Zaloguj się aby komentować








![Ponad 170 tys. książek z bazy Books3 zostało wykorzystanych do zasilenia baz danych dużych modeli językowych (LLM) jakich jak LLaMA [ENG]](https://cdn.hejto.pl/uploads/posts/images/250x250/603140954d649cad03ded8b6b45fb402.jpg)

